How to Deliver Traffic to a Service in a Data Center
How to Deliver Traffic to a Service in a Data Center
Let’s Briefly Recap: What Are Data Center Networks?
For about two decades now, the entire networking engineering and architecture industry has shifted from so-called “classic three-tier architecture” (with access layer devices, aggregation layer devices, a core, and some external gateway) to Leaf-Spine networks (also known as Clos architecture).

Leaf-Spine—well, obviously, because there are leaves, spines, super-spines, and all that jazz. I think anyone who’s ever Googled or asked their senior (or junior, more up-to-date colleague) about “data center networks” has probably seen a diagram like this.
So, Why Clos? Why Did the Industry Adopt It? What Are the Benefits?
- First thing that comes to mind? Scalability, of course. The topology makes it easy to add new devices and increase bandwidth without redesigning the whole architecture. Got some new servers? Just plop a new switch here, plug it in, fire up LACP. Architecturally, nothing’s changed, but now we can handle more servers.
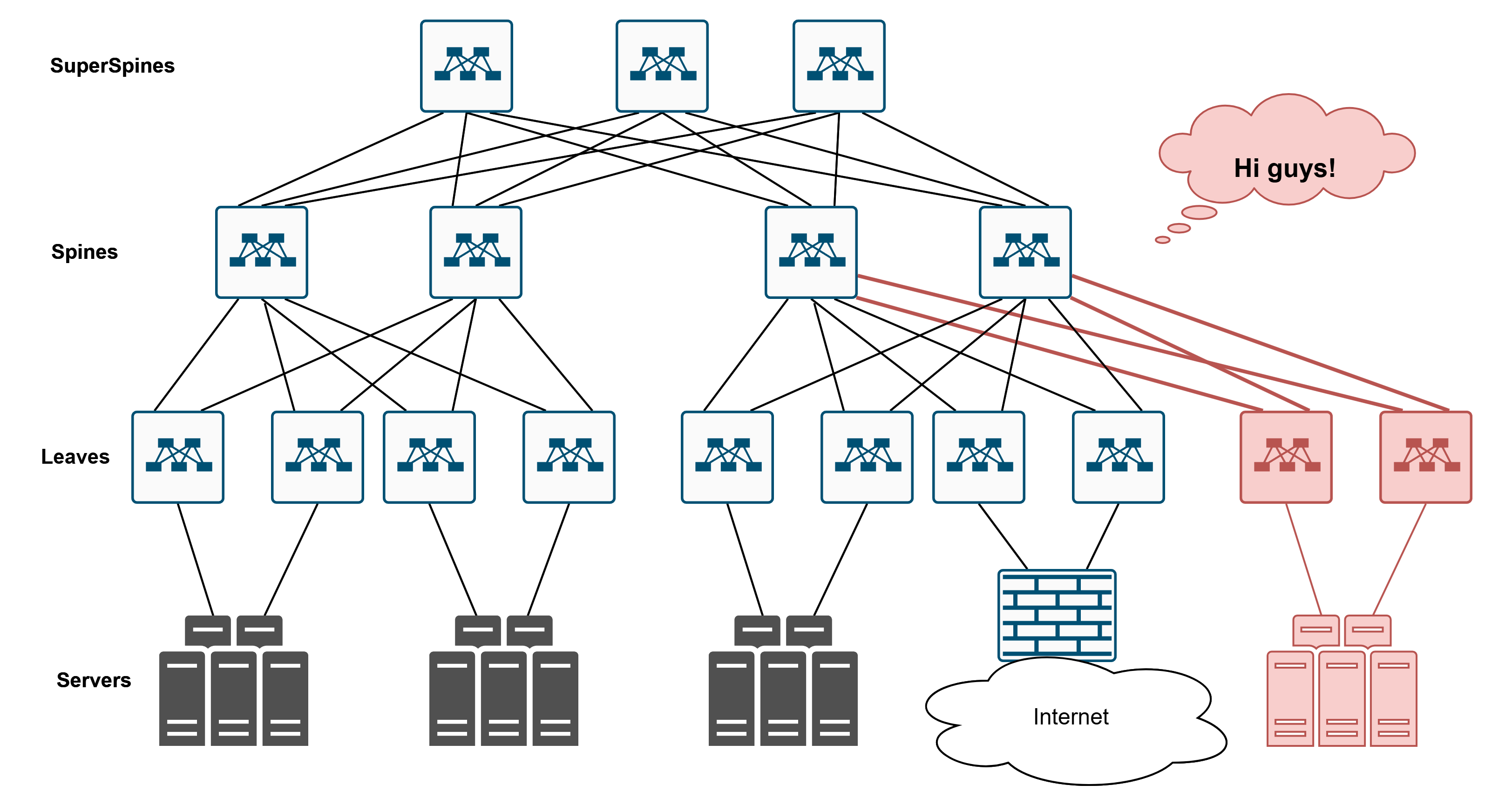
- Second — redundancy galore. This isn’t just for fun. It’s all about fault tolerance. This one dies? That one dies? No big deal, traffic just takes a detour. That one over there fails? We’ll live. The network becomes resilient.
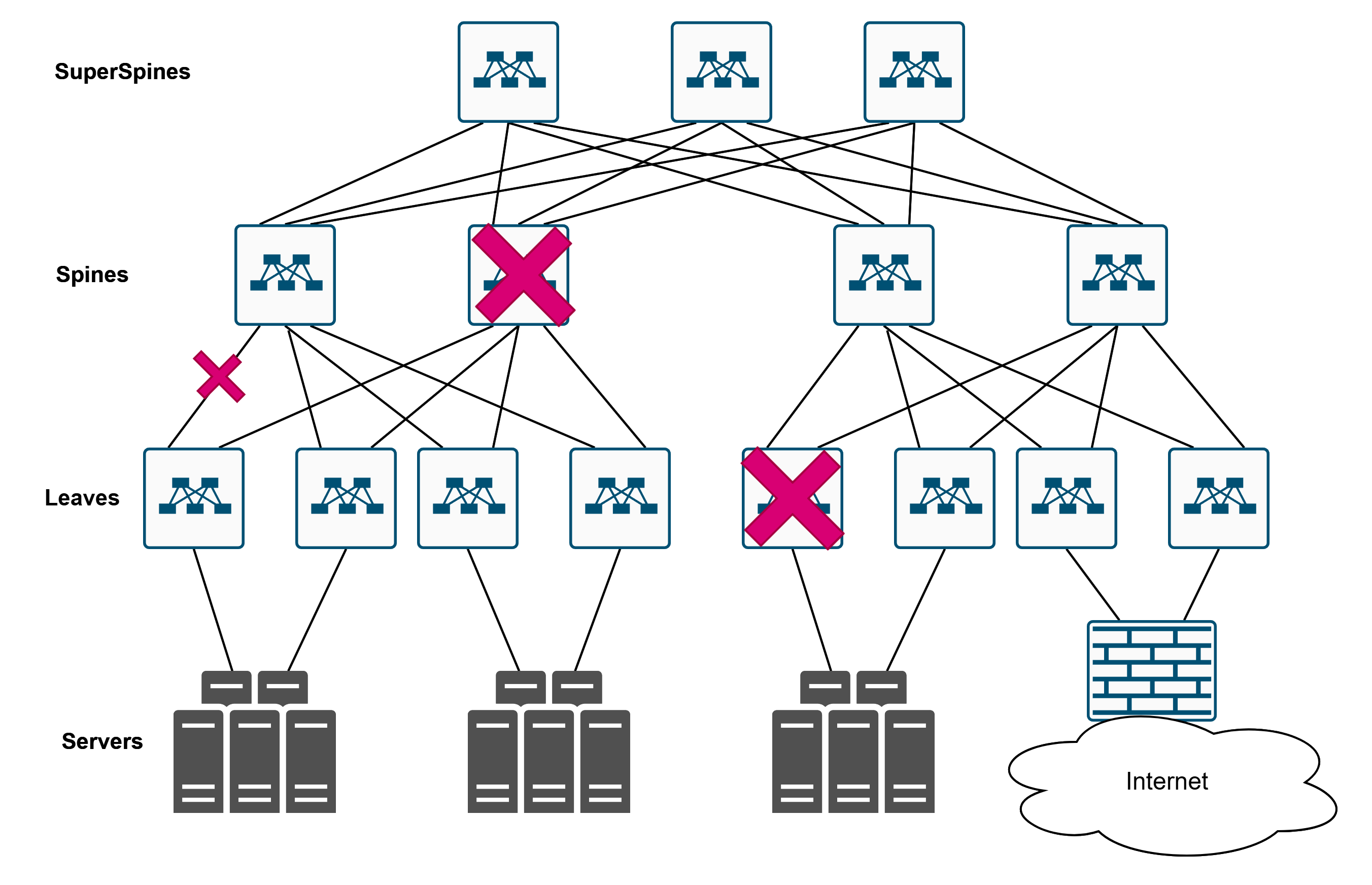
All these links can be used at the same time — that’s the beauty of it. Usually, we’re talking about an IP fabric running dynamic routing protocols that allow multiple active paths, unlike some shady STP that just blocks half the links.
Versatility. Since it’s an IP fabric, any service can run on top of it. VPNs, GRE, VXLAN—you name it. The IP fabric is built to support any overlay network that delivers traffic to the end service.
“Cost efficiency” often gets mentioned, but that’s… debatable. Sure, it sounds good, but you’d have to crunch the numbers. A bit of a questionable bullet point, if you ask me.
But let’s be real: nobody cares about networks — they all care about services. As network architects and engineers, we must never forget that people only care about services. And for those services to work? You guessed it — you need networks. Simple as that.
So, What Do Services Need (Besides the Network, Obviously)?
Easy Scalability: Say we build a cat picture website, and suddenly it blows up. We need to add another server and balance the traffic. The infrastructure should handle this seamlessly. More users? More storage, because storage is also a service — and it better scale too.
Fault Tolerance: If our cat-pic server dies, users should still get their daily dose of whiskers. Even if an entire data center goes dark, the user shouldn’t notice—because cats are non-negotiable.
Efficient Resource Usage: This is where cloud tech shines. Why did cloud computing take off? Because of elastic resource management. Today you have 10 users, tomorrow 100, and the day after — back to 15. You need to scale flexibly, and that’s where containers and other modern cloud solutions come in.
Deploying a Cat Picture Website!

Alright, so we’ve decided to build a cat picture website and want it to be scalable and reliable. What steps do we take to ensure it’s fault-tolerant?
- Deploy a bunch of servers hosting cat pics
- Add data center/region-level redundancy
- Set up global geo-distribution
- Configure load balancing
- ???
- PROFIT!
And that’s where the questions start popping up…
Let’s say we’ve built the infrastructure hosting our cats:
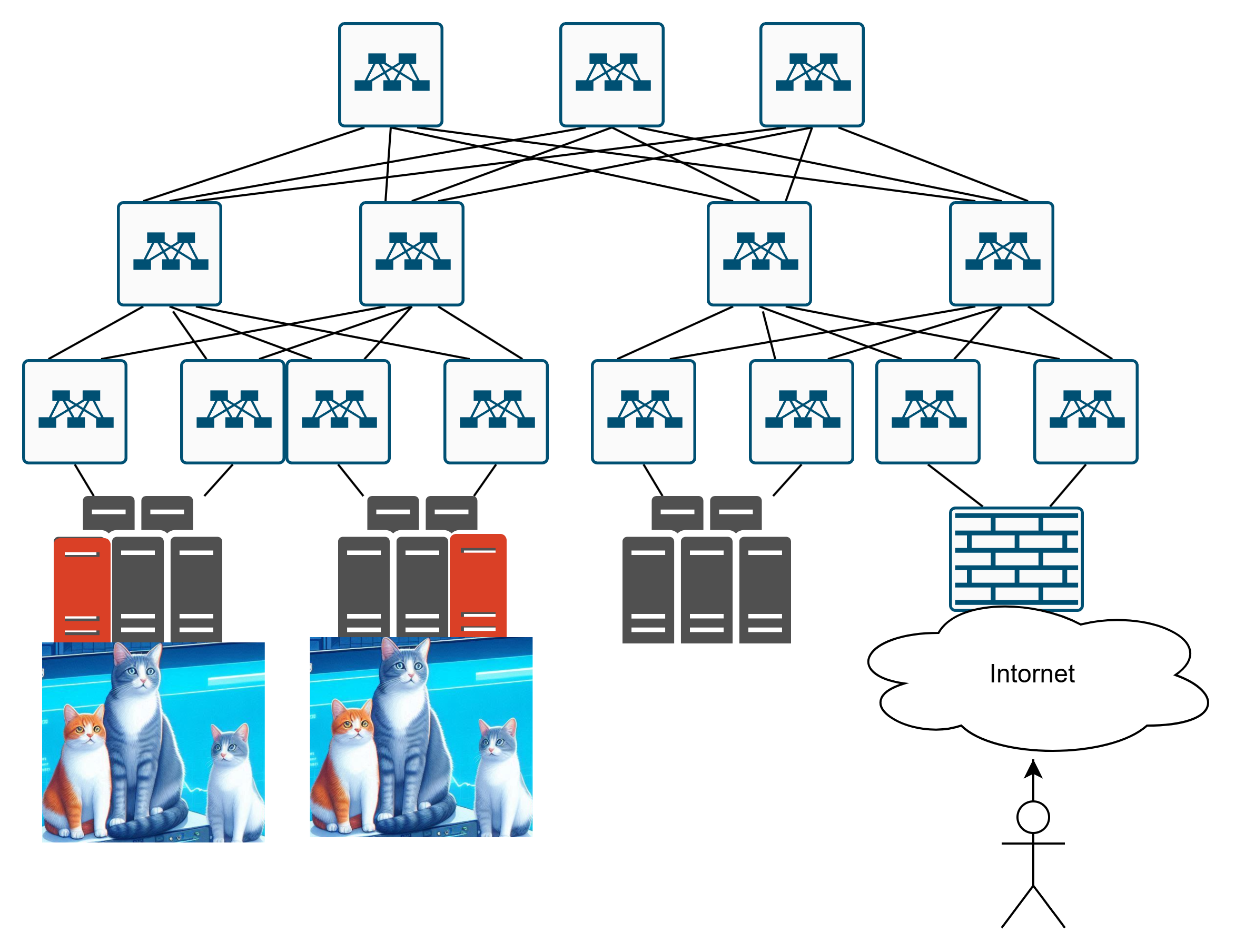
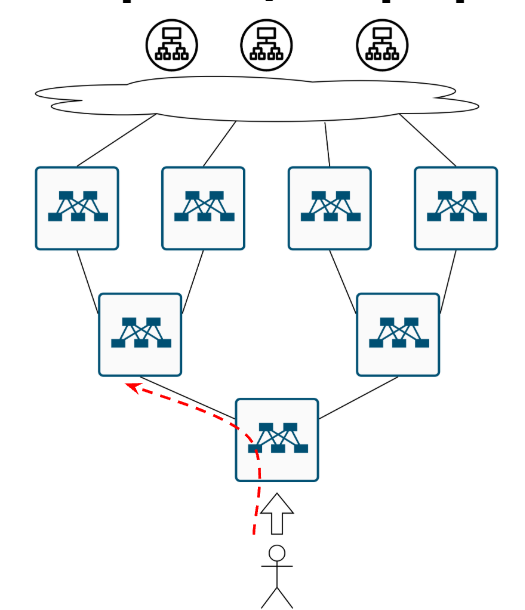
How Does the User Reach the Cat Website If There Are Multiple Servers?
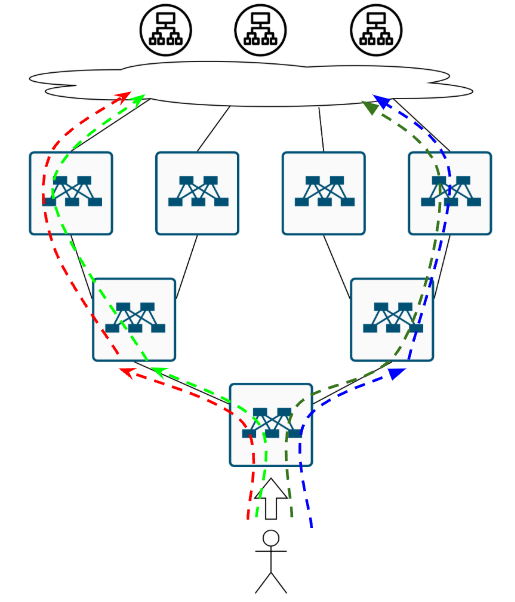
A user arrives at the data center, and… now what? Where do they go? To these cats?
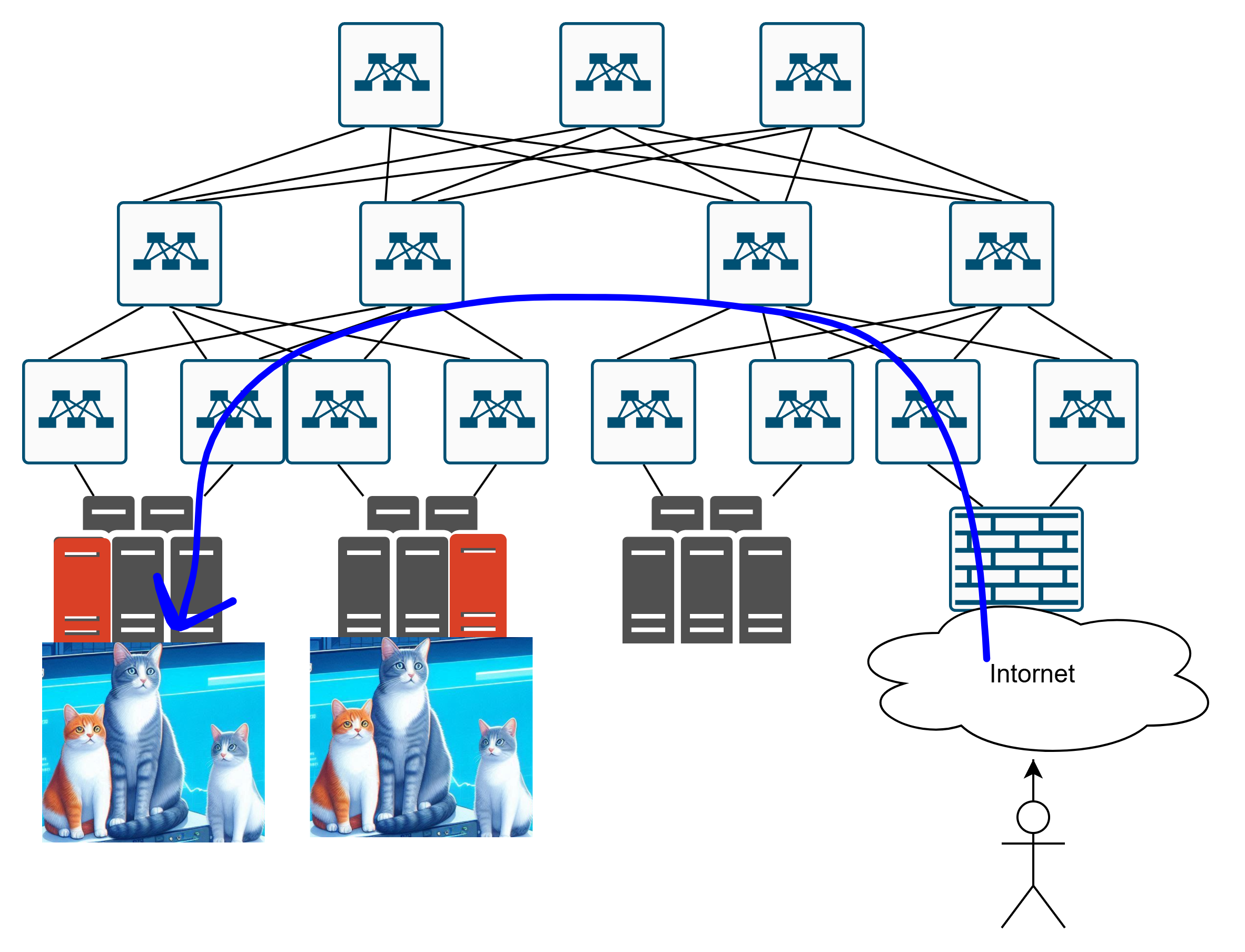
Or to those cats over there?
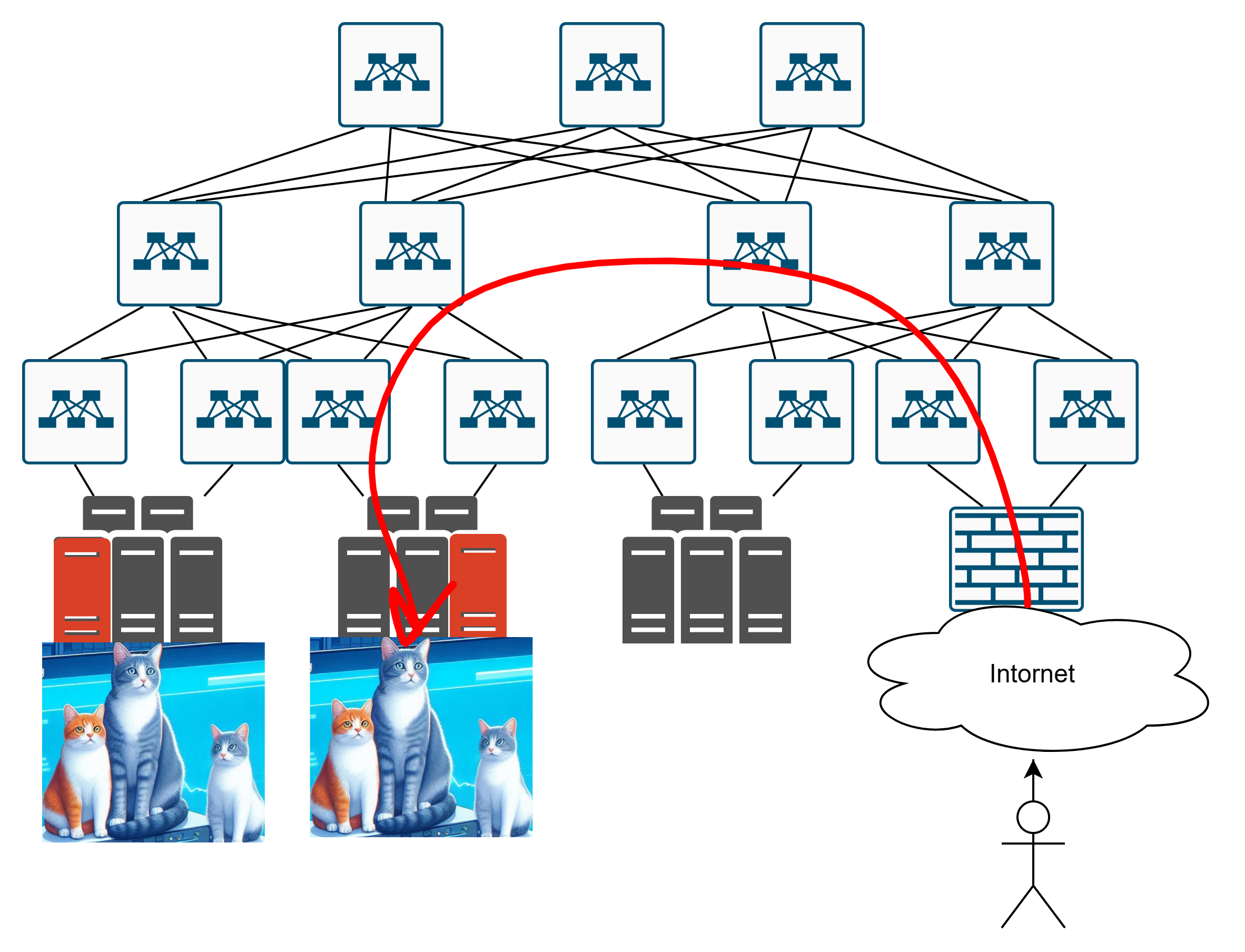
And if they’re heading to the second set of cats, how exactly do they get there? Like this?
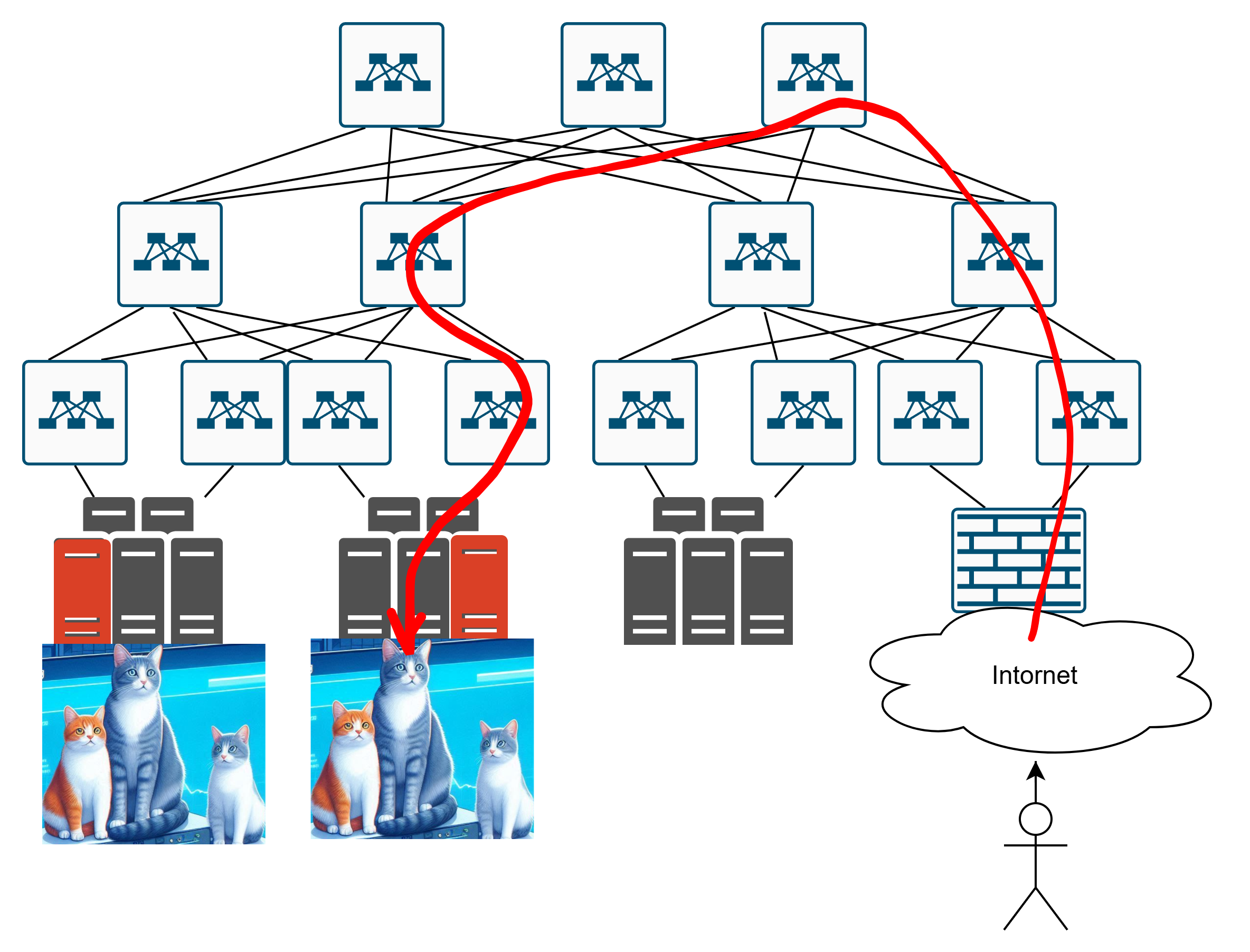
Or maybe like this?
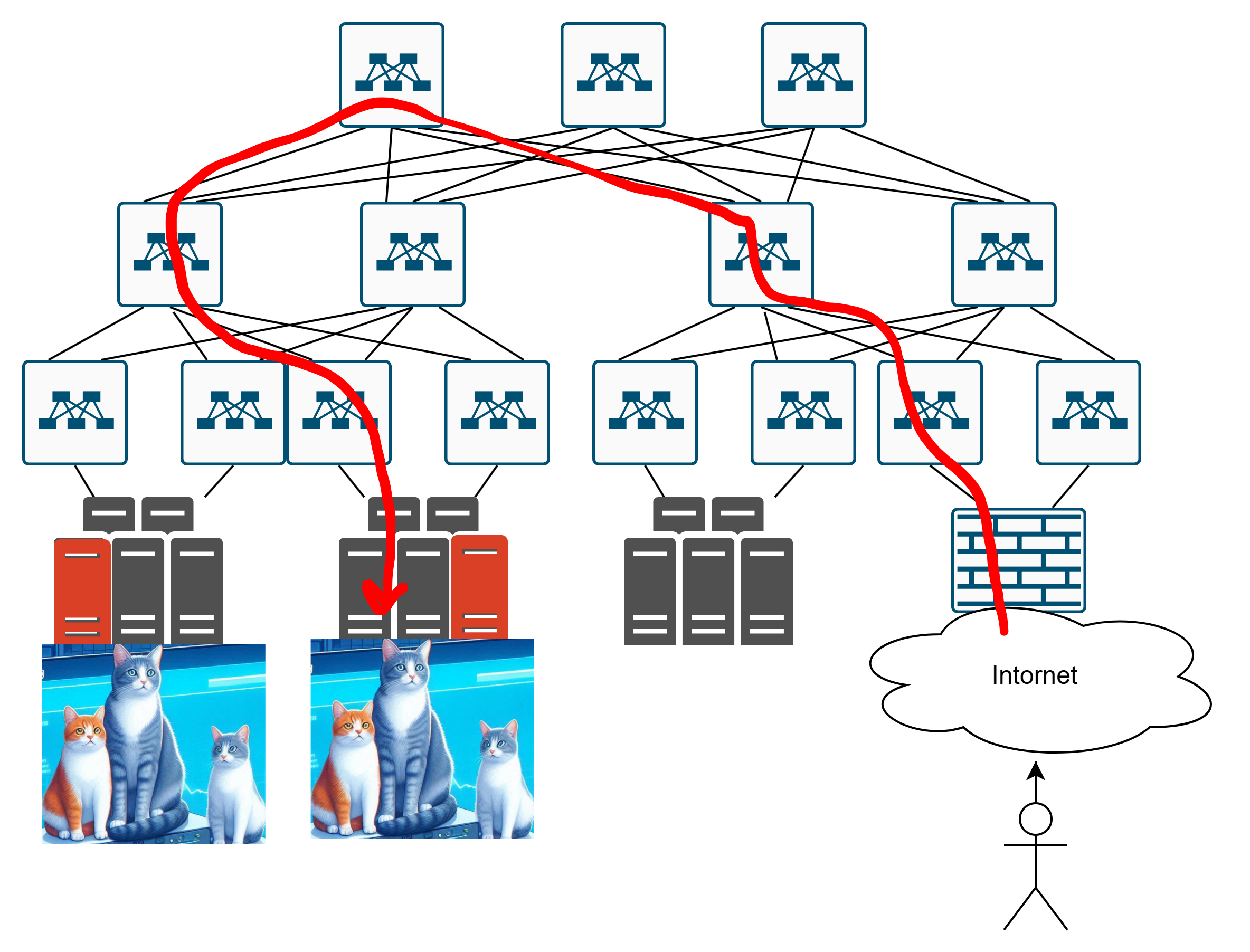
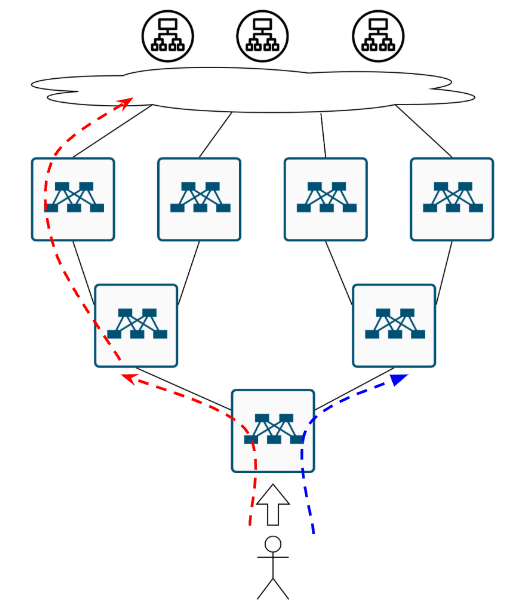
But let’s say we somehow solved that problem.
How does a user reach the cat website when there are multiple data centers?
As we scale up, we quickly outgrow a single data center - not to mention those racks consuming 5KW each. Now we’re building a multi-zone cat hosting platform. Each zone is a data center in a different region/city, connected via some Data Center Interconnect (DCI) - dark fiber, colored fiber, L2 VPN, doesn’t matter:
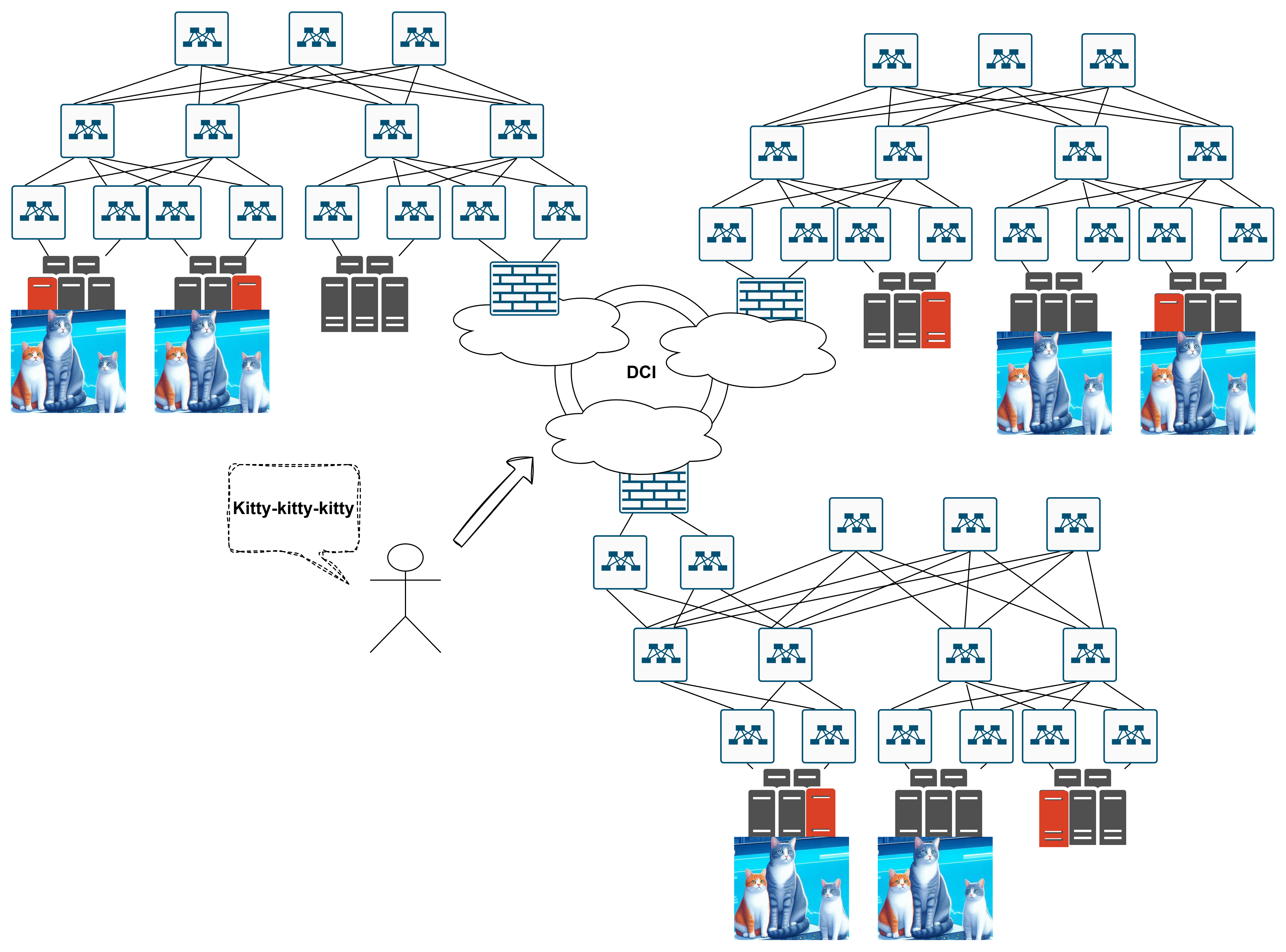
Which way to the cats? No idea :(
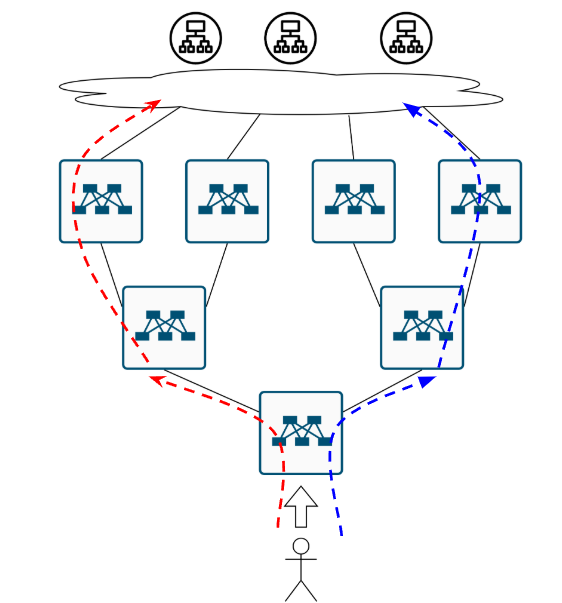
How does a user reach the cat website when cats are scattered worldwide?
Cats always follow the same pattern - they become insanely popular! Now your cat content is in global demand. Time for worldwide expansion - deploying regions in the US, Europe, Botswana, and of course Magadan (cool Russian city)!
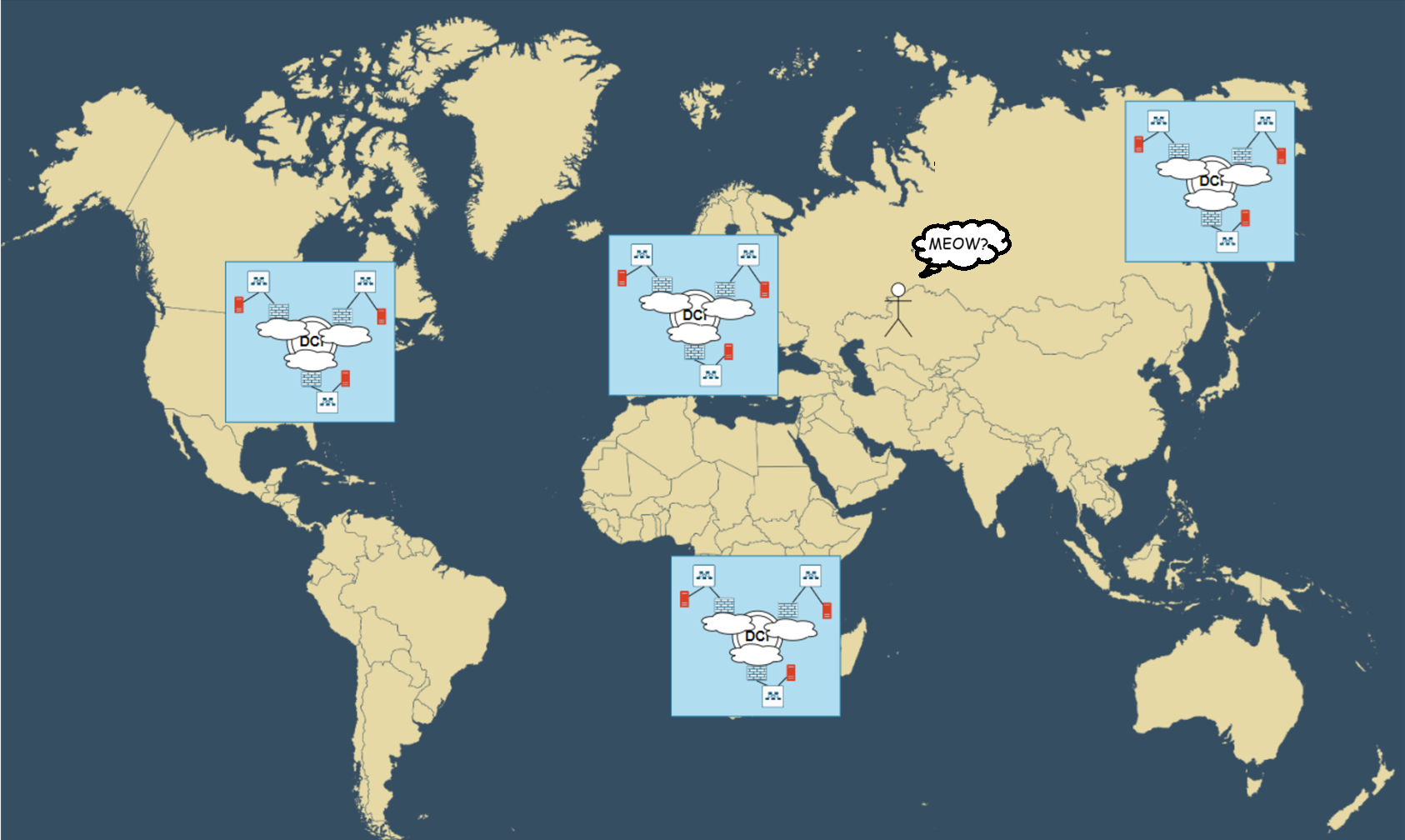
Where should our proud Kazakh friend go to see cats? Huh?
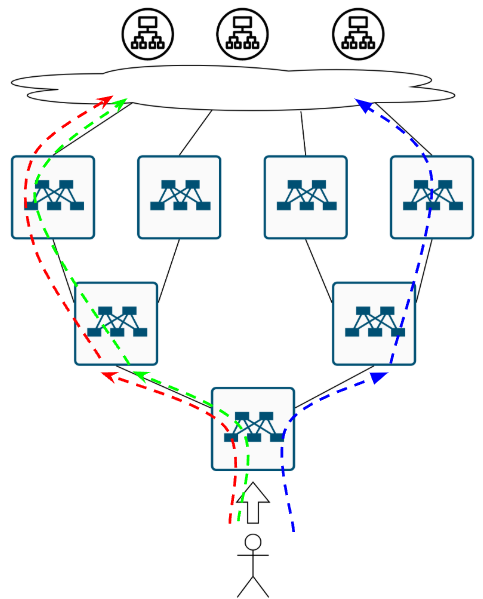
Trying to solve these pesky questions
Let’s try tackling these issues. How DO we deliver this traffic anyway?
Which region should handle user traffic?
We’ve got users in Kazakhstan and cat servers spread worldwide. What are our options?
The lazy approach: Just announce our public IP via BGP with no special policies and see what happens. Some rudimentary load balancing will occur naturally - some traffic goes to one DC, some to another. But anyone who’s worked at an ISP or understands internet routing knows calling this “optimal distribution” would be… well, hilarious. Most likely, traffic will become heavily imbalanced - some DCs will get flooded while others sit half-empty.
The DNS round-robin approach: Distribute IPs globally. Take four addresses: announce one from the US, another from Europe, plus Botswana and Magadan. List them as four A-records for the same DNS name. Pros: Traffic should distribute somewhat evenly between regions. Cons: DNS roulette often misfires, and our Botswana visitor might end up chasing cats all the way to Magadan :(
The smart solution - Global Server Load Balancing (GSLB): This is intelligent DNS that considers client location and directs them to the nearest DC: Kazakhstan → Europe, Canada → US. Seems perfect, but in practice still requires constant monitoring and tweaking - traffic has a mind of its own. When properly configured though, it outperforms any round-robin. This way, our Kazakh user will likely hit European servers, while Canadian users land in the US..
How to Route Traffic Within a Region?
Now we need to distribute traffic within a single region. The balancing methods here are essentially the same.
The “do nothing” approach: Rely on raw BGP. Just announce the same IP from all data centers and see what happens. Maybe it’ll somehow balance itself—just make sure to peer with different ISPs in different locations. Fingers crossed!
DNS roulette, regional edition: Give each DC its own unique /24 prefix while maintaining a shared backup /22. If one DC goes down, traffic automatically fails over to the others via the shared network. Does it work? Technically, yes. Is it perfect? Well….
The smart regional balancing: Let traffic go to any DC in the region — whether it’s “Equinix FR2” or “Digital Realty FR5”. Doesn’t matter as long as it’s in our network. Then let MPLS TE (Traffic Engineering) handle the rest: it automatically distributes traffic between DCs based on their capacity:
Got 2 active servers in one DC and 1 in another? The first gets 2/3 of traffic, the second gets 1/3.
No magic — just an intelligent system maintaining balance based on actual server count.
How to implement? I have no idea. That’s your problem now — my job here is to drop genius ideas xD
Alright, we’ve got traffic inside the DC — now what?
Which Server Should Handle Traffic Inside the Data Center?
What can we do on this level?
The do absolutely NOTHING approach: Rely on pure randomness (okay, slightly exaggerated) and let ECMP in the fabric handle it via anycast — all servers share the same IP. But here’s the catch: If the service dies but the server is still up and advertising its IP, traffic will happily flow into a black hole. No health checks, no mercy. (*To be honest, if you’re running BGP-ECMP in your fabric, you’ll probably need to enable and tweak it a bit)
Add a dash of brains: Deploy a basic L3/L4 load balancer. The cheapest option? Linux’s IPVS module with simple keepalived checks.
Now at least we know which servers are actually alive and ready for traffic — and which are just zombie boxes waving their IPs from the grave.
Smarter? Yes. But still pretty dumb — it only looks at IPs and ports, with zero insight into what’s inside the packets.
Enter the Application Load Balancer: This is where the real magic happens. NGINX or HAProxy dig into HTTP traffic like a pro.
Want to route requests by URL? (/cats → one cluster, /dogs → another).
Need sticky sessions? Cookie-based server binding, done.
SSL/TLS? Offload it here—the backends have enough problems already.
Only downside: You gotta know how to cook this dish properly.
The Perfect Load Balancing Hierarchy in a Data Center
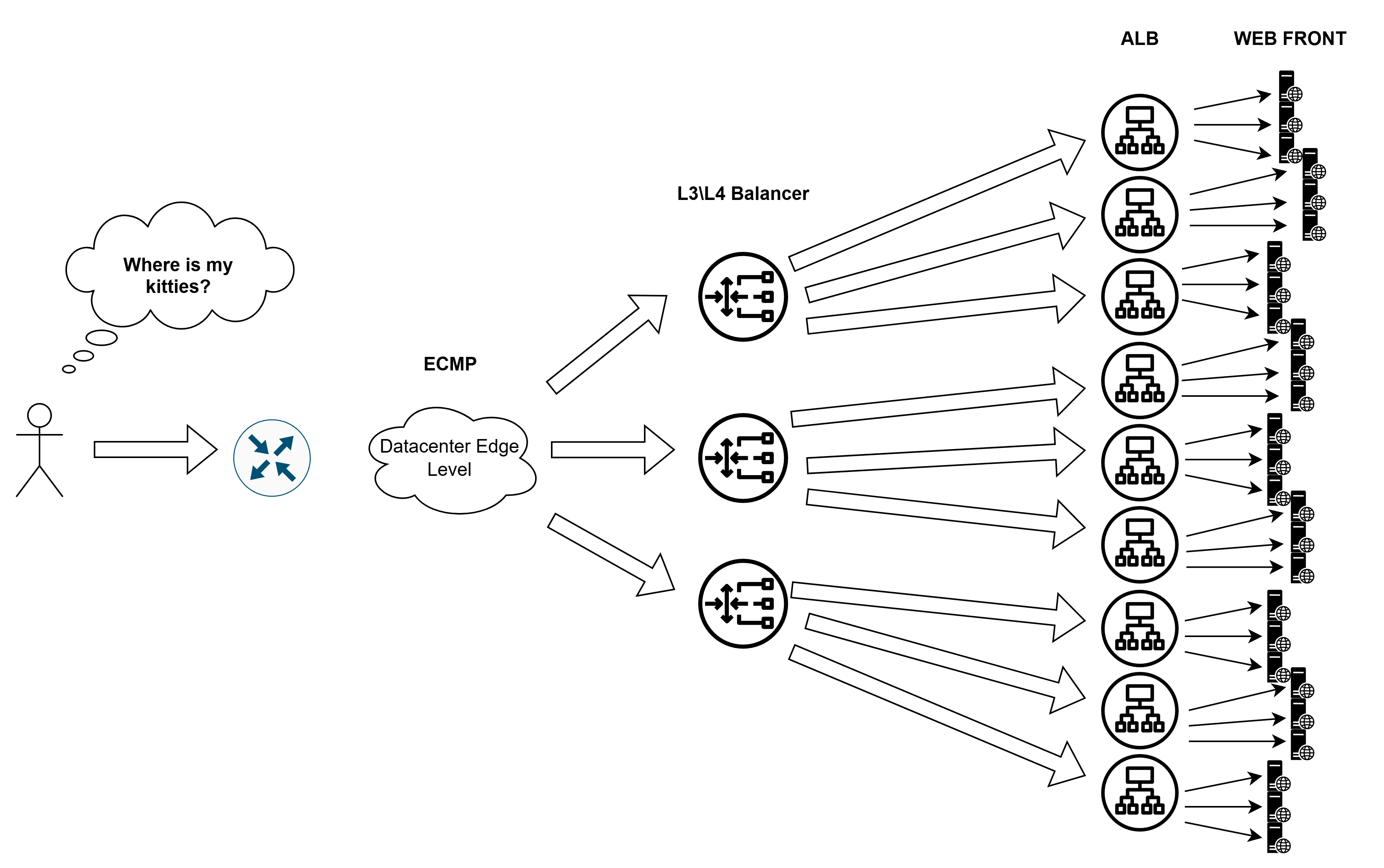
1. The Front Door (ECMP + Anycast)
User traffic enters the fabric through plain IP routing. ECMP spreads it across L3/L4 balancers (NLBs) using good old-fashioned routing. Anycast lets all NLBs respond from the same IP. Simple and efficient, but not exactly brainy.
2. The Middle Layer (L4 → L7)
This is where the magic happens:
- NLB (L3/L4) receives traffic and tunnels it (GRE/IPIP) to ALBs
- Runs health checks on backend services
- Can use DSR (Direct Server Return) to bypass NLB for return traffic
- Distributes load across fleets of Application LBs
3. The Final Touch (L7 Balancing)
ALBs operate at application level:
- Decipher HTTP/HTTPS like seasoned cryptanalysts
- Route by URL (/cats → cluster1, /dogs → cluster2)
- Offload SSL/TLS
- Maintain sticky sessions via cookies
Why This Rocks:
- Elastic scaling: Can add NLB/ALB layers as needed
- Optimal paths: DSR reduces return traffic load on NLBs
- Only real limits: Physics (cables, server capacity)
Scaling Up!
1. City-Level (Equinix FR2 or Digital Realty FR5)
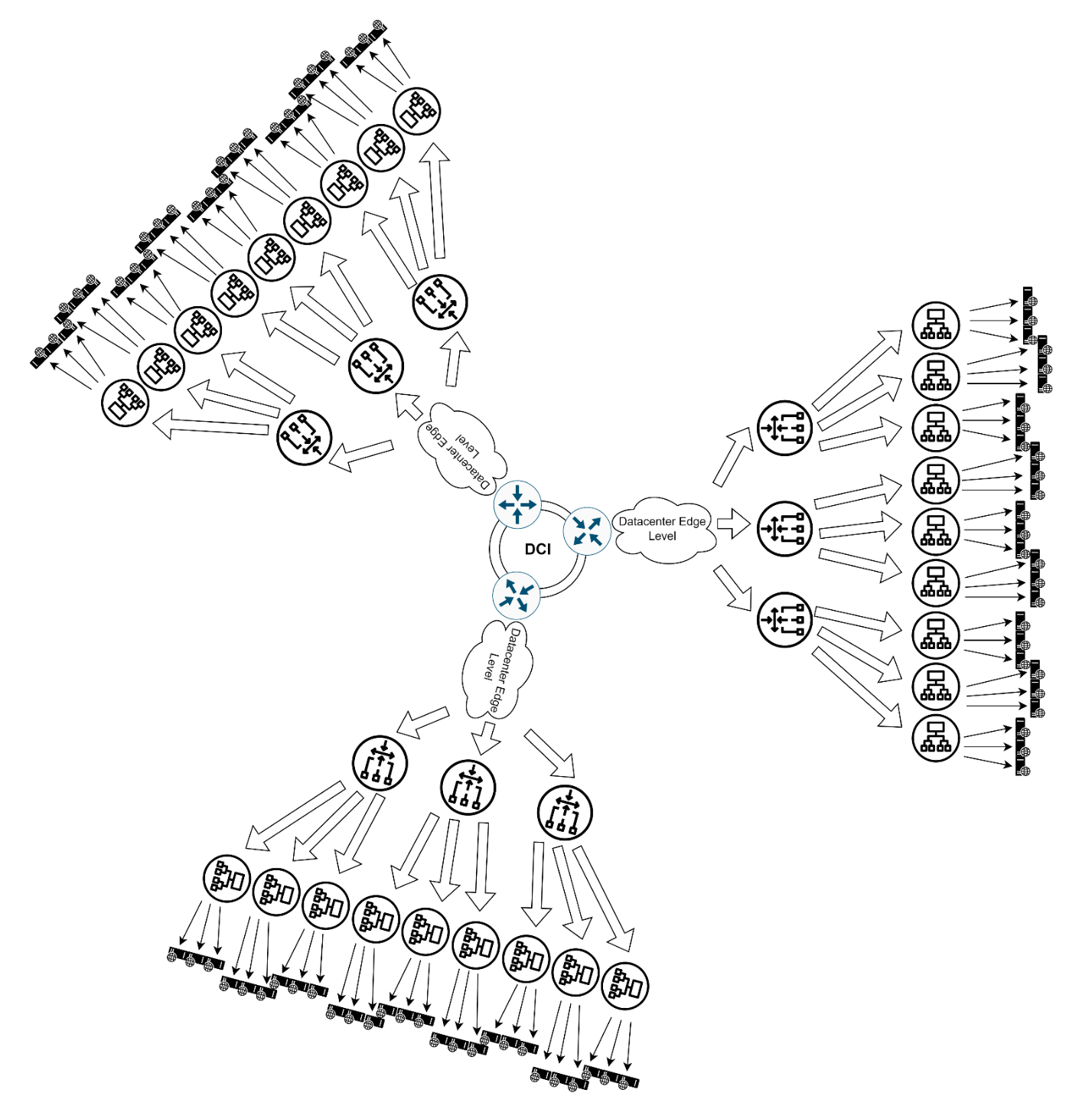
When one data center isn’t enough, we add regional load balancing - multiplying data centers with a sprinkle of DCI-level logic (or without it)
2. Global Scale
When we outgrow cities:
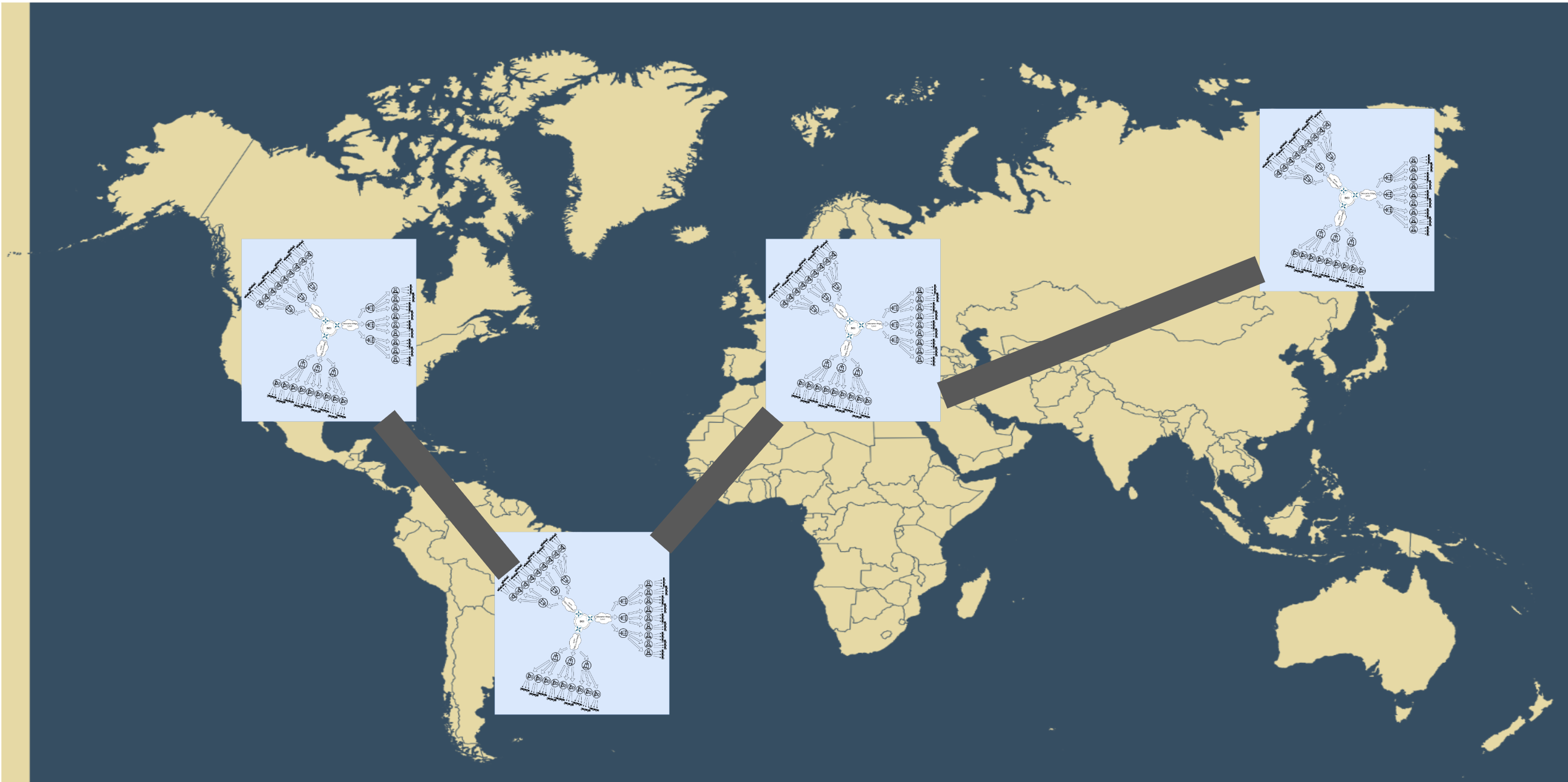
- Continental Points of Presence (Europe, Asia, US)
- Same principles, but with extra layers:
- Geo-DNS (Berlin client gets Frankfurt DC IP)
- Intercontinental Anycast (BGP + localized anycast IPs)
- Global GSLB considering:
Cross-continent latency
Legal restrictions (EU GDPR)
Regional transit costsне
“This. Is. Fucking. Awesome.” (c) Anonymous Network Engineer
Load balancer solutions example

L7 (Application Load Balancers)
- Nginx
- HAProxy
- Traefik
- Envoy
- Istio (Service Mesh)
L3/L4 (Network Balancers)
- IPVS (LVS)
- F5 BIG-IP
Cloud solutions
- AWS ALB
- GCP HTTP(S) LB
- Azure Application Gateway
There was an idea to include a practical demo on basic ECMP+Anycast+Linux IPVS load balancing in a lab… but I can’t be bothered. Do it yoursel
The Quirks and Caveats of ECMP Load Balancing
Now let’s talk about those little nuances you should keep in mind when working with ECMP.
Who Qualifies for Equal-Cost Status?
How do routes even get into this exclusive ECMP club? The requirements aren’t that strict actually:
- Your hardware must support ECMP (though in 2025, who doesn’t?)
- Routes must come from the same routing protocol (and that protocol must support multipath). Looks like it’s default behavior for OSPF\ISIS, but not for BGP*
- Routes must have identical protocol metrics
*BGP gets an asterisk because multipath isn’t always enabled by default, and if you’re running eBGP in your fabric, don’t forget about bgp multipath as-path relax
The Distribution Dilemma
Okay, let’s say we’ve got ECMP up and running. Now we face the million-dollar question:
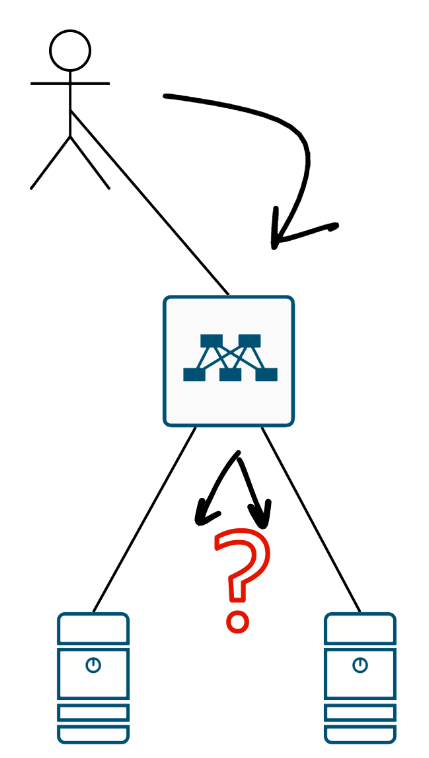
So what?
When a switch has two “equal” paths, how should it distribute traffic? There are two approaches - both with their own pitfalls.
1) Per-packet Round Robin
This might work fine… in theory.:
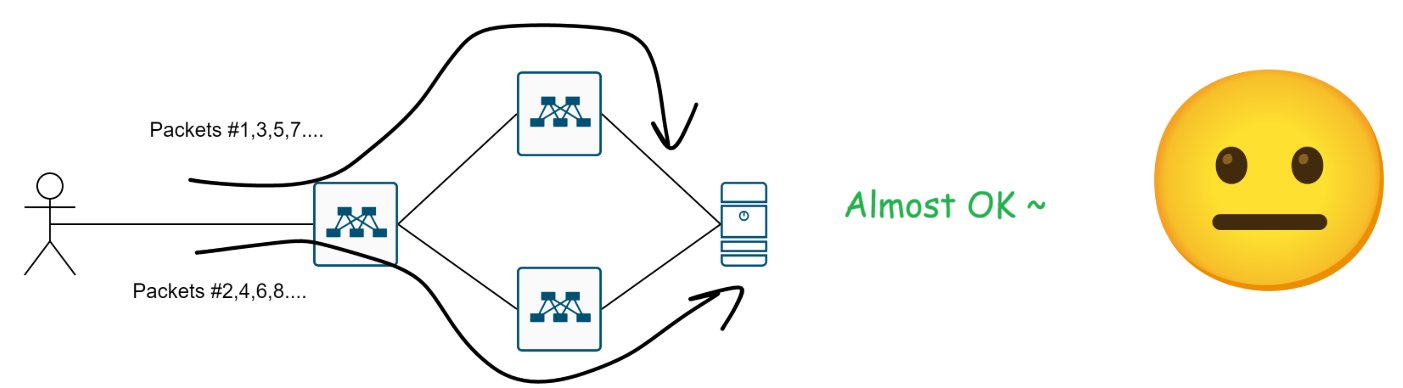
But then TCP Anycast comes along and ruins everything…
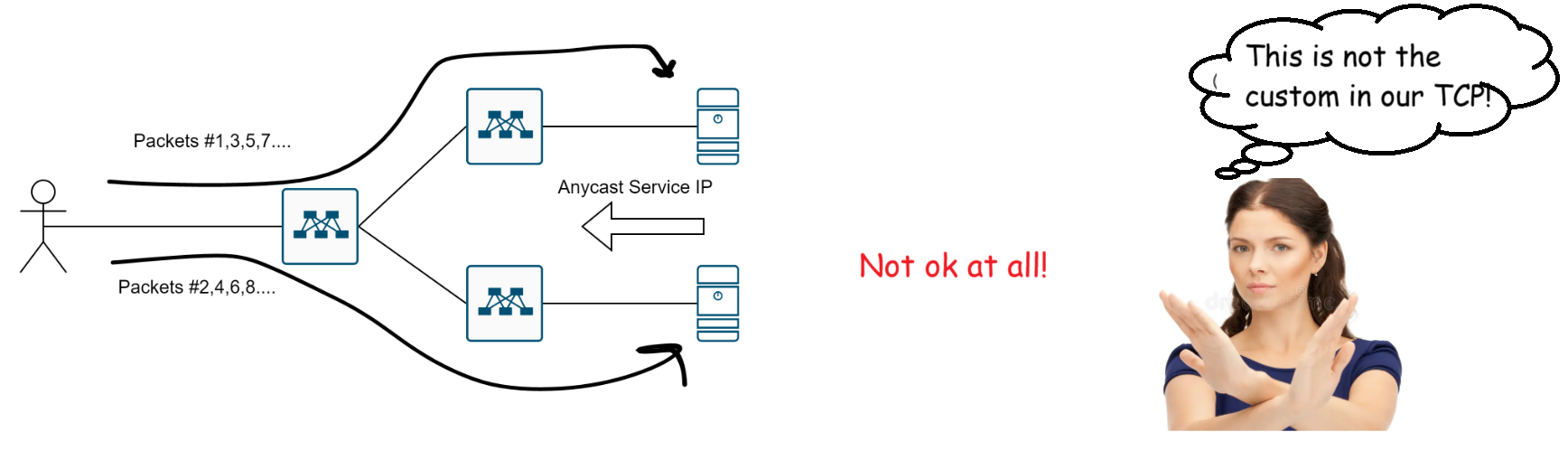
Which is why cool kids use option two.
2) Per-flow Hashing
Here we calculate a hash based on flow parameters:
- MAC addresses + EtherType for L2
- 5-tuple (src/dst IP, src/dst port, protocol) for TCP/UDP
So we get this simple scheme::
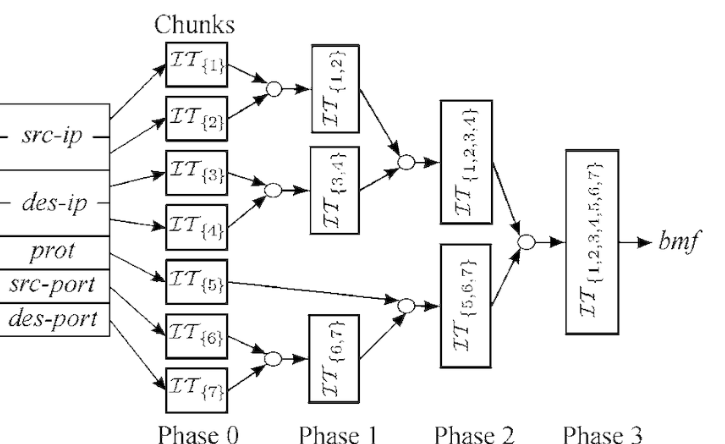
Calculate a hash for the flow
Map that hash to an output port
When new packets arrive, recalculate the hash
If it matches existing flow → same port
New flow? Assign new port and update the table
This way, all packets in the same TCP session will always* take the same path…
*“Always” being a relative term, of course…
Imagine our pristine, flowless network:
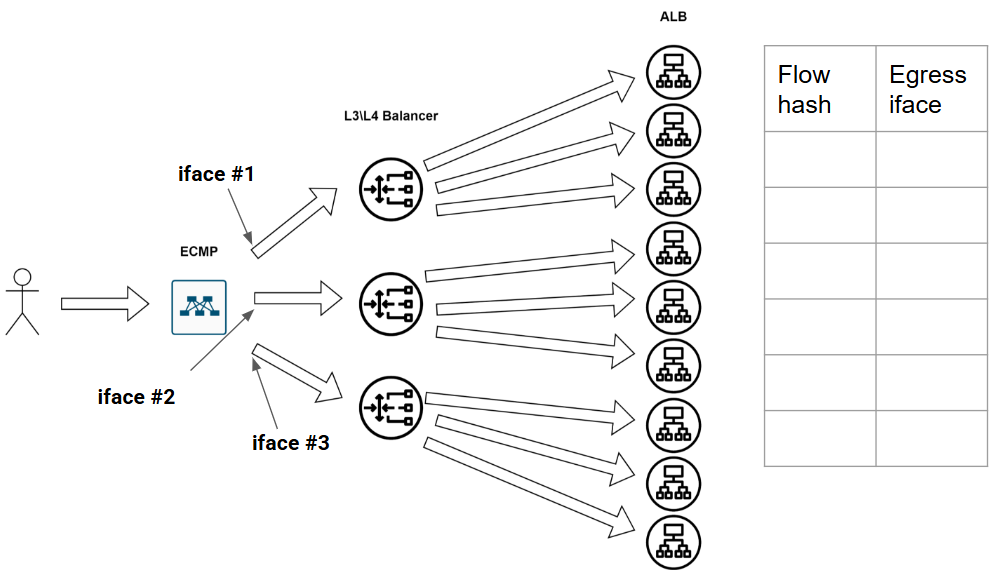
Then the first flow arrives. We calculate its hash and assign it to the first interface, updating our table:
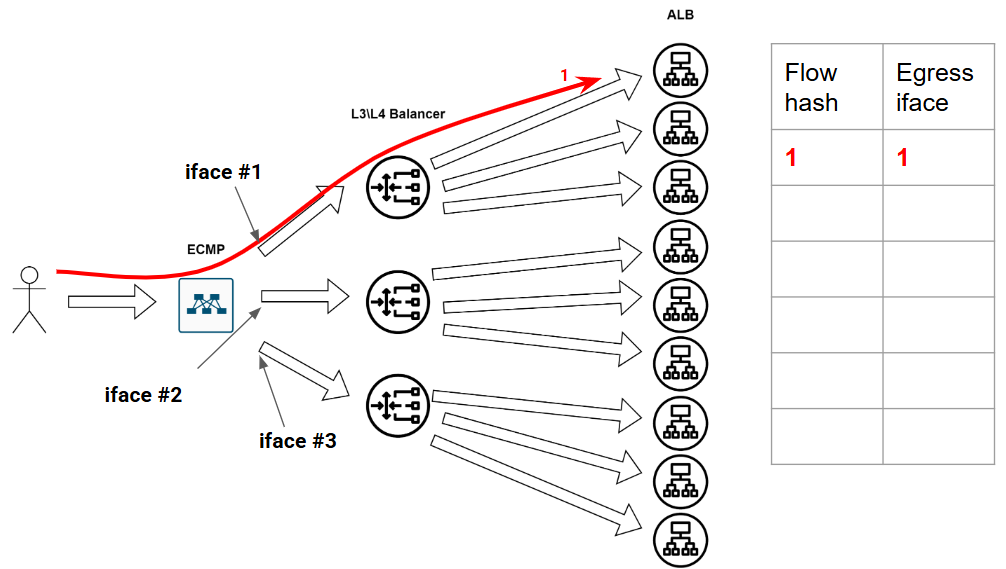
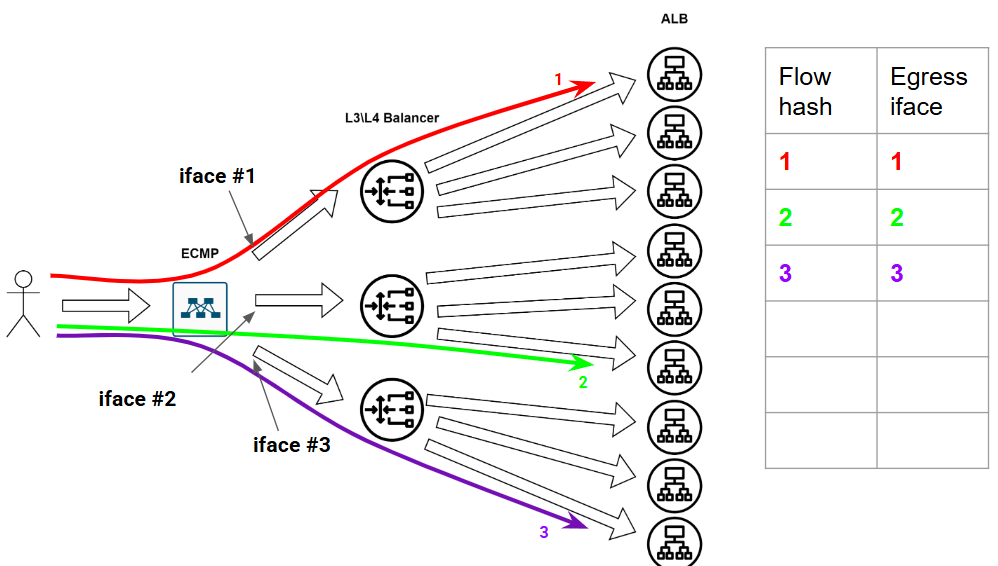
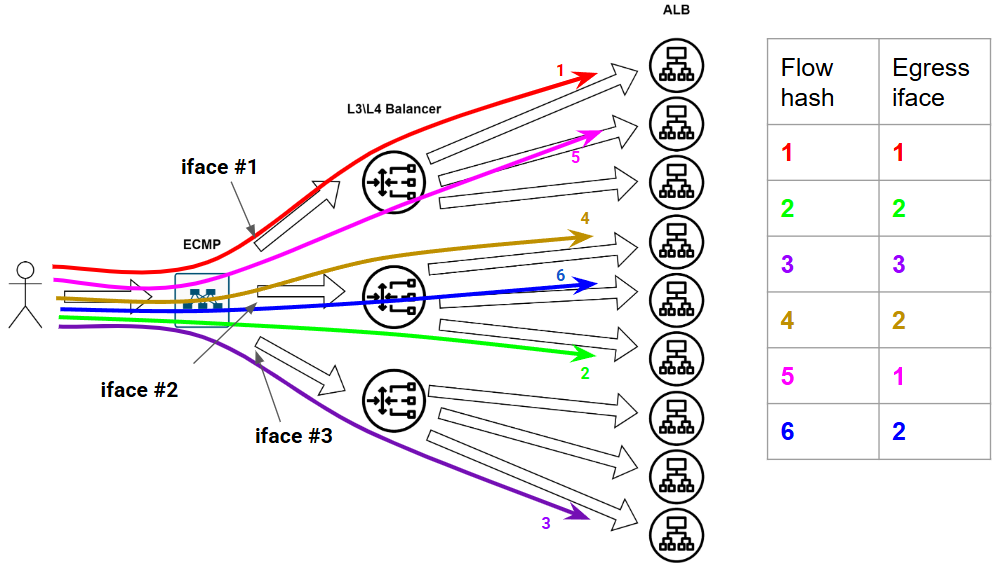
Seems perfect, right? …Until the network gremlins strike. And they always strike — this is the way.
When Disaster Strikes Say one of our load balancers kicks the bucket. POOF! That interface is gone. Chaos ensues:
Our beautiful flow table? Obliterated.
Existing TCP sessions? Annihilated.
Half-downloaded cat pics? Lost to the void.
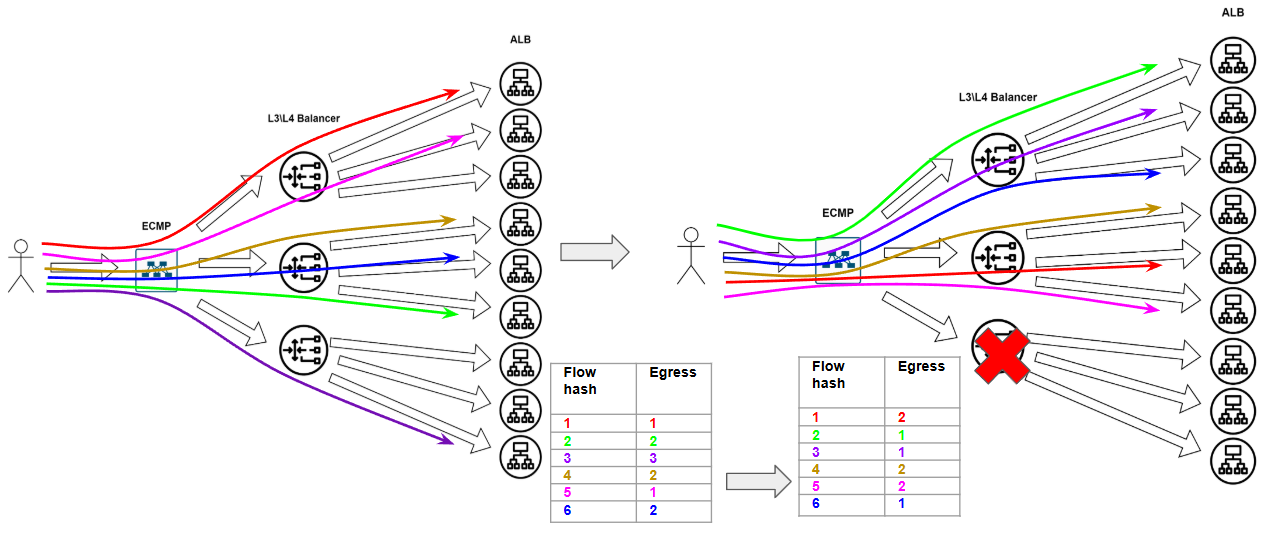
Only Flow 4 gets lucky, landing in the same bucket as before. The rest? Total reshuffle.
So what now? (Dramatic pause…)
Resilient Hashing
Turns out, the smart folks have already figured this out and called it resilient hashing (or consistent hashing for the nerds).
For the deep dive, check out NVIDIA’s docs. But I’ll summarize it here — borrowing their diagrams, of course.
Case 1: When an Interface Dies
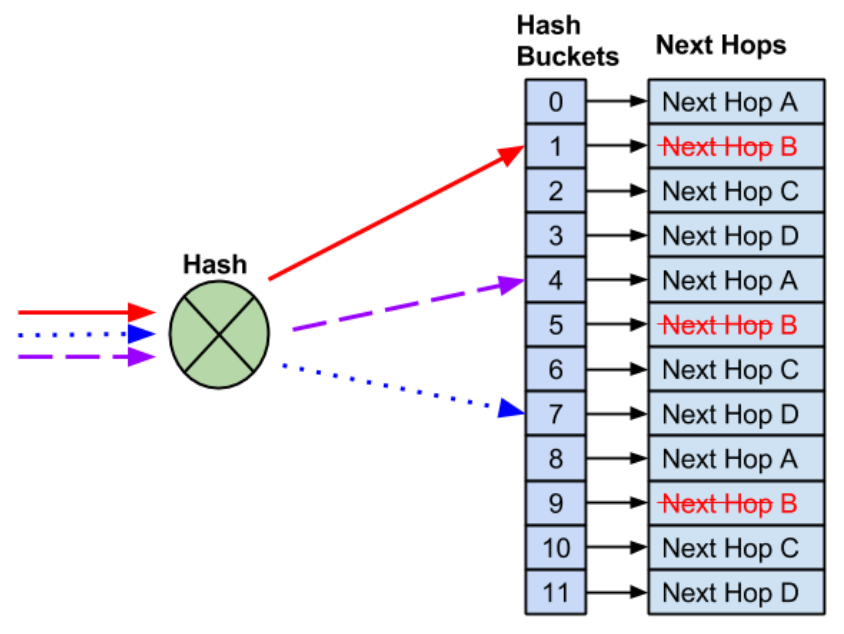
Rule #1 of resilient hashing: Don’t touch the healthy flows! Instead of reshuffling everything, we just fill the dead next-hop’s spot with the remaining live ones.
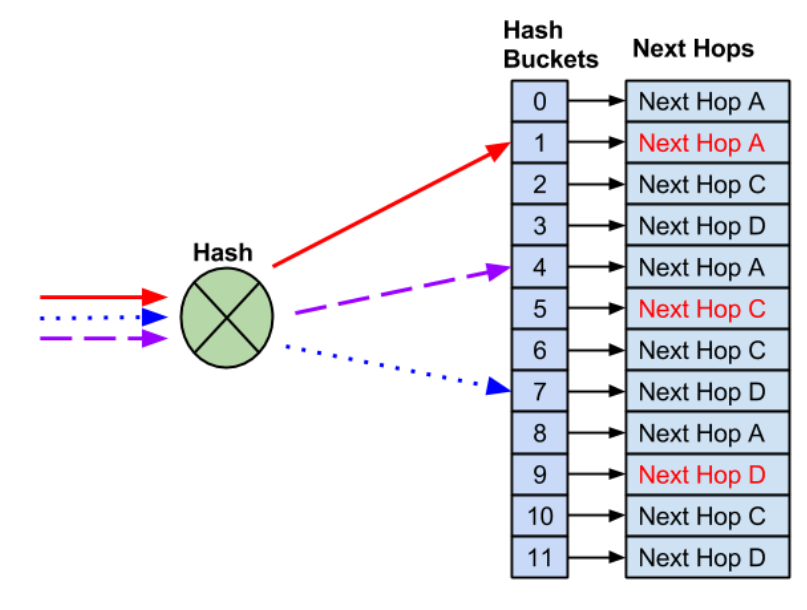
Result:
- Working flows? Untouched.
- Broken path? Patched up.
- Cat videos? Still streaming.
Case 2: When a New Interface Joins
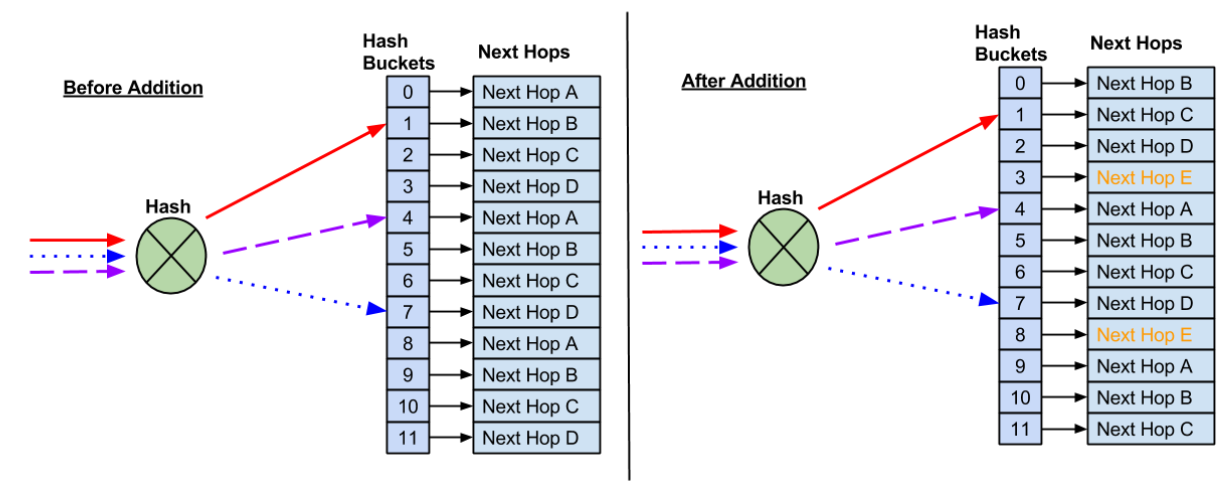
Here’s the irony: A new balanceer causes MORE chaos than a dead one!
Existing flows get redistributed to accommodate the newcomer.
Suddenly, TCP sessions are bouncing around like ping-pong balls.
Moral of the story?
- 🚫 Avoid deploying new balancers during peak traffic.
- 🚫 Steer clear of flapping routes.
- ✅ Test changes when the internet isn’t watching.
Traffic Polarization
Here’s another fun gotcha that everyone tends to forget. Most DC network fabrics use hardware from the same vendor — and even if the models differ, their hashing logic (how they map flows to next-hops) is often identical. This can lead to… unexpected behavior. A flow hits the first switch, and ECMP sends it left::

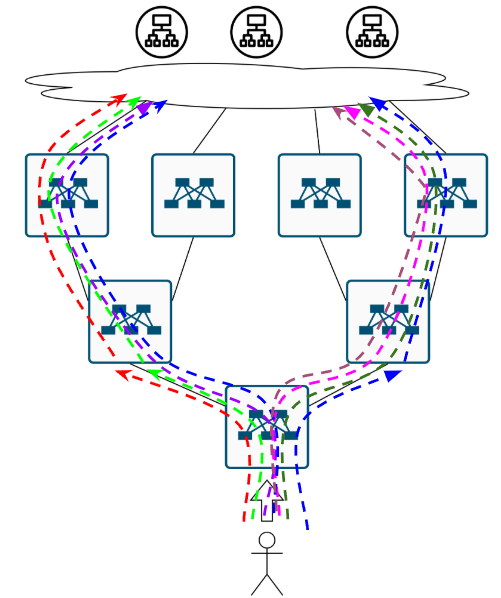
That’s the stench of polarization — where traffic piles up on the same paths instead of spreading evenly. The solution? A simple, elegant, blockchain-powered…

…SEED.
Vendors add a seed value (usually configurable) to vary hashing between devices.
Even with identical hardware, different seeds break the symmetry.
Result:
Flows distribute more evenly.
No more “left-left-right-right” predictability.
The network smells fresh again.
The Final Boss
Just when we thought we’d solved all our hashing and polarization woes they show up…

…again.
Who Are “They”?
Mice flows:
iny, short-lived bursts (like HTTP requests). Fast, sensitive to latency, and very annoying when delayed.
Elephant flows:
Gigantic, bandwidth-hogging beasts (think backups or video streams). They don’t care about latency—they just crush everything in their path.
Why Is This a Problem?
A mouse arrives. Sent up one path
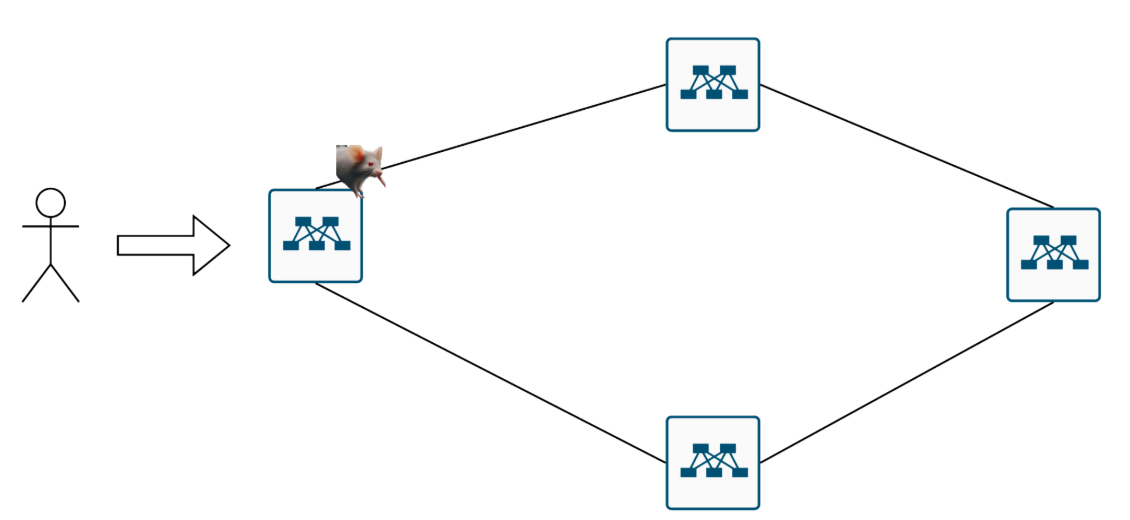
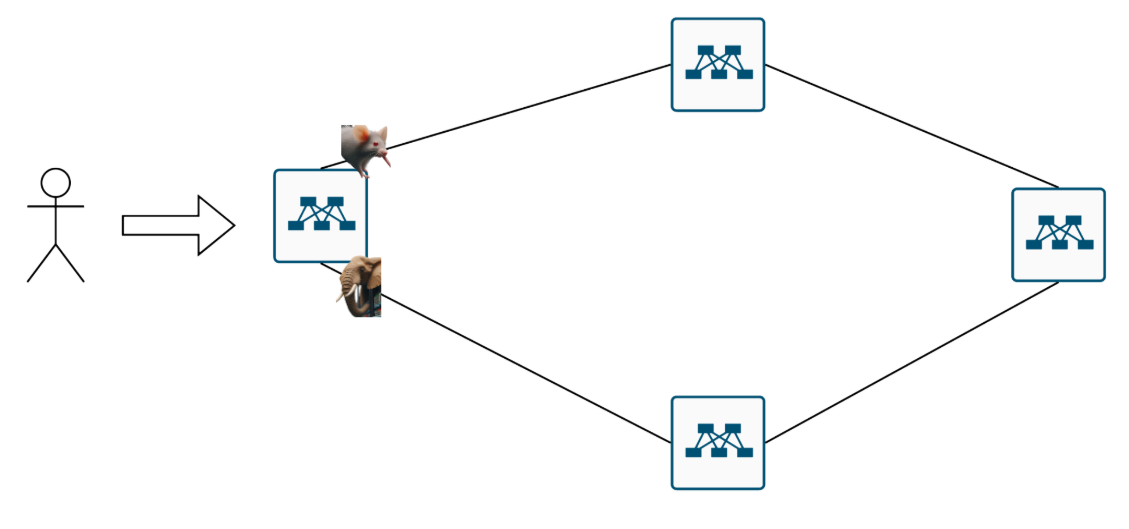
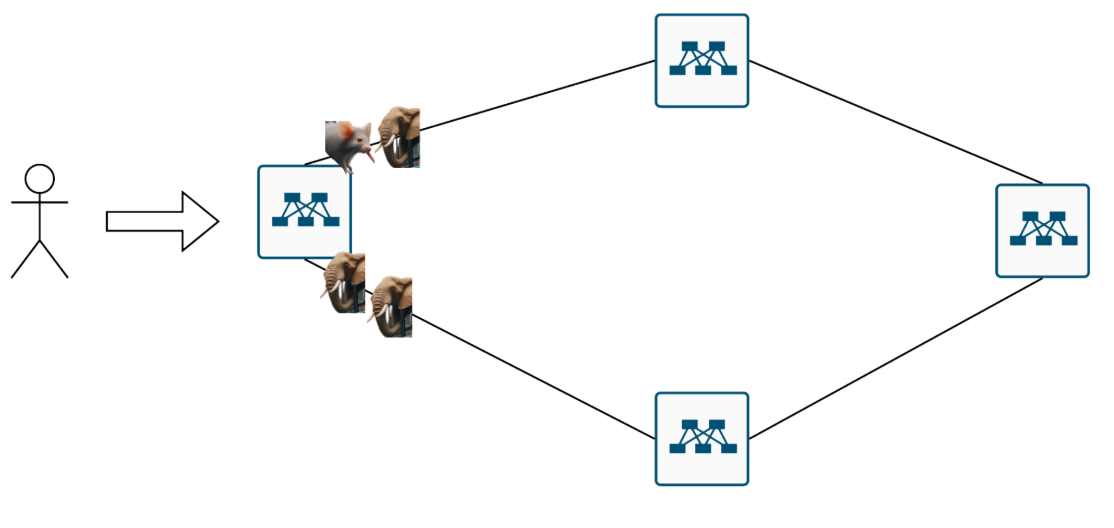
More mice Result:
- By flow count, links look balanced.
- By bandwidth, one path is drowning in elephants while mice starve.
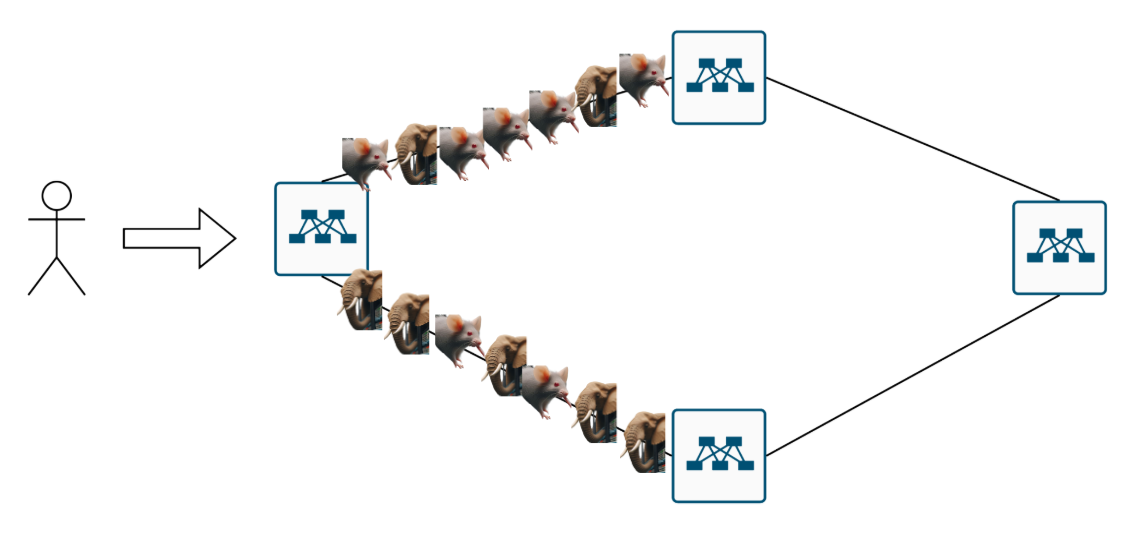
How to Tame the Beasts?
Introducing… flowlets! A flowlet is a chunk of a TCP flow, split by natural gaps (like waiting for ACKs). Basically, TCP’s way of saying: “I’m taking a coffee break.”
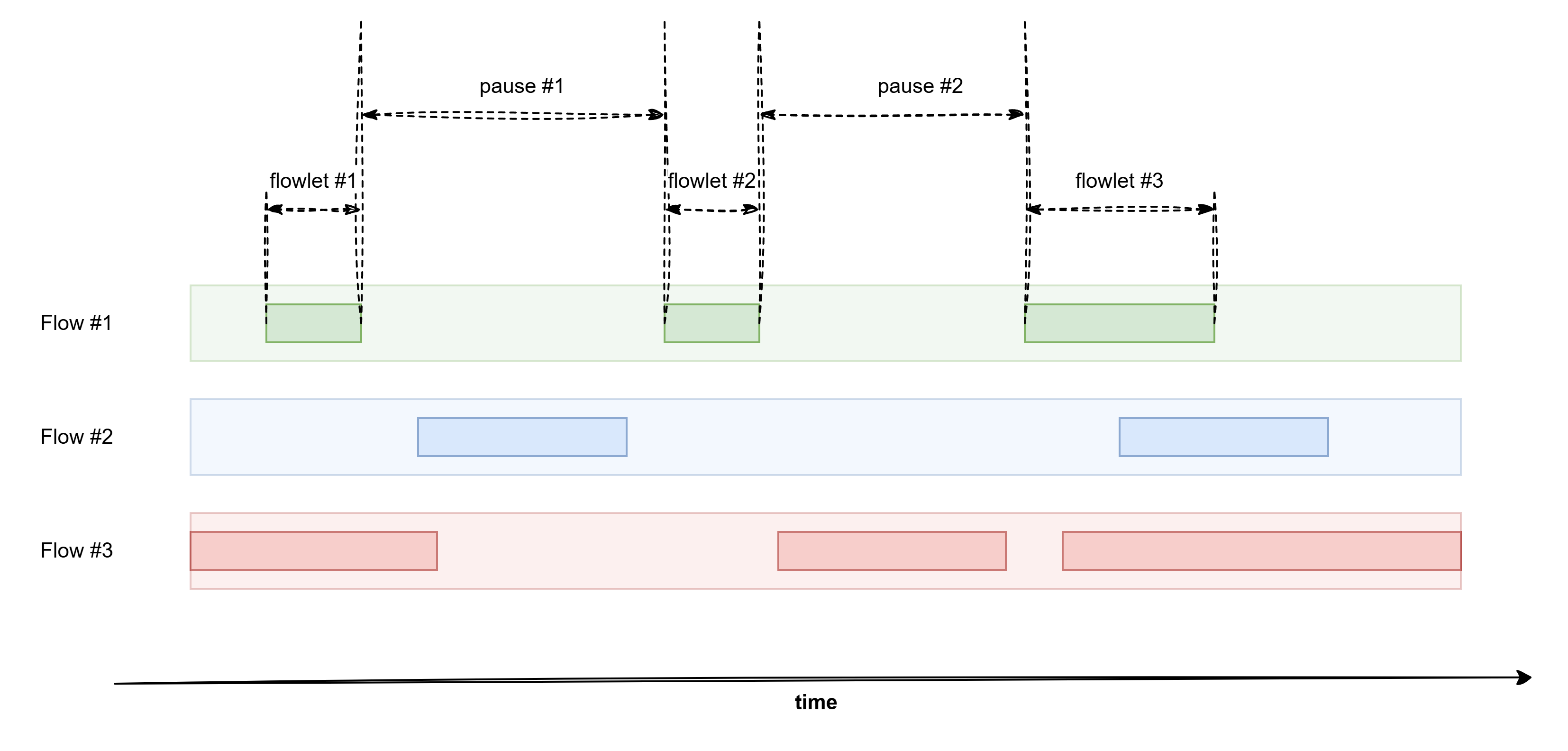
Flowlet Balancing Magic Unlike dumb ECMP (which locks a flow to one path forever), flowlet balancing:
- Spots gaps in traffic.
- Redirects the next chunk to a less congested path.
Boom! Now even a single flow’s chunks take different routes. Mind = blown.
The Catch (Because There’s Always One) There’s just one critical condition: flowlet #2 must NEVER arrive before flowlet #1 - otherwise everything turns into complete nonsense!
How This Could Happen Theoretically, this could occur if:
The switch decides to send flowlet #1 via “the Australia route” (damn, that’s one sprawling fabric!)
Meaning: it takes a path whose latency compared to flowlet #2’s path is longer than the inter-flowlet gap
Let’s Break It Down:
Assume the expected gap between flowlets = 50 μs
Flowlet #1’s path latency = 80 μs
Flowlet #2’s path latency = 20 μs
Timeline of Events:
At time t0: send flowlet #1 (arrives at t0+80 μs)
Wait 50 μs (at t0+50): send flowlet #2 (arrives at t0+50+20 = t0+70 μs)
The Disaster:
- Flowlet #2 arrives at t0+70 μs while #1 arrives at t0+80 μs.
- 10 μs of out-of-order delivery!
(Classic case of “we tried to improve things but made them worse”)
So, the idea is solid, but our network needs some serious brainpower to pull this off:
It must know the exact latency of every possible path.
It needs to predict how long the gaps between flowlets will be.
This looks like a job for AI… or in other words, hardcore math. Want to see how hardcore? Check out:
- CONGA paper (the math behind Cisco’s magic)
- Early flowlet concepts
I don’t actually read these — such kind of formulas scare me:
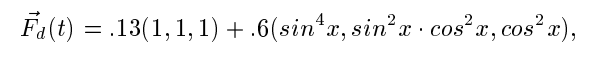
Vendor Wars: Who’s Doing What?
Cisco ACI: Implements this as Dynamic Load Balancing. Very SDN, very fancy.
Juniper: Said “screw it” and shoved it straight into hardware as Adaptive Load Balancing. Be like Juniper.
Anycast Warning ⚠️ Using flowlets with anycast? Tread carefully.
Your fabric might not realize different paths lead to different servers.
Result: TCP sessions could implode. Regularly.
TL;DR: Key Takeaways
No silver bullet — just trade-offs.
Know your traffic: Mice need speed; elephants need lanes.
Mix strategies: ECMP here, flowlets there.
Test, fail, fix, repeat.
Meeting adjourned. Nothing left to see here. 🚪