Как в датацентре доставить трафик до сервиса
Вспомним немножко, что же это такое — сети дата-центров?
В целом, наверное, уже второе десятилетие, как вся индустрия сетевой инженерии и сетевой архитектуры пришла к тому, что сети в дата-центрах перешли от так называемой “классической трёхуровневой архитектуры” (где у нас есть железки уровня доступа, железки уровня агрегации, кор и какой-то внешний выход) к сетям Leaf-Spine (или она же Clos-архитектура).
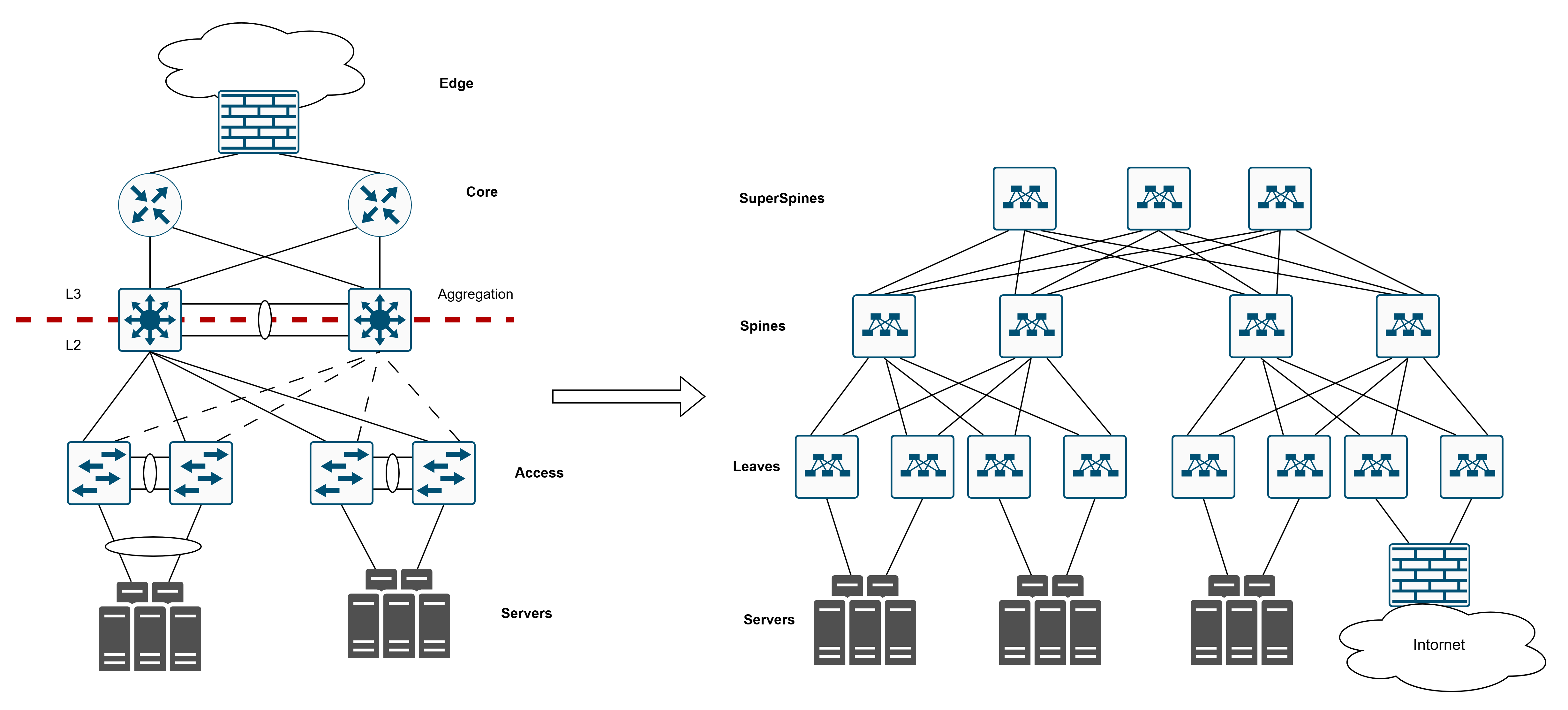
Leaf-Spine - ну очевидно, потому что есть листья (Leaf), потому что есть хребты (Spine), есть супер-хребты, и всё такое. Думаю, всем, кто хоть раз вводил в гугле или спрашивал у своего старшего (или у младшего, более свежего, товарища) “сеть дата-центра”, скорее всего, выдавалась какая-то такая картинка.
Итак, почему в принципе Clos? Почему индустрия пришла к этому? Какие преимущества есть у данной топологии?
- Первое, что приходит в голову, — конечно, масштабируемость. Топология позволяет легко добавлять какие-то новые устройства, увеличивать пропускную способность без изменения архитектуры. Появились у нас какие-то новые сервера? Вот здесь вот мы поставили новый свич, ткнули его сюда, подняли LACP. По факту, с точки зрения архитектуры, ничего не изменилось, но мы таким образом увеличили количество серверов, которое можем обслуживать.
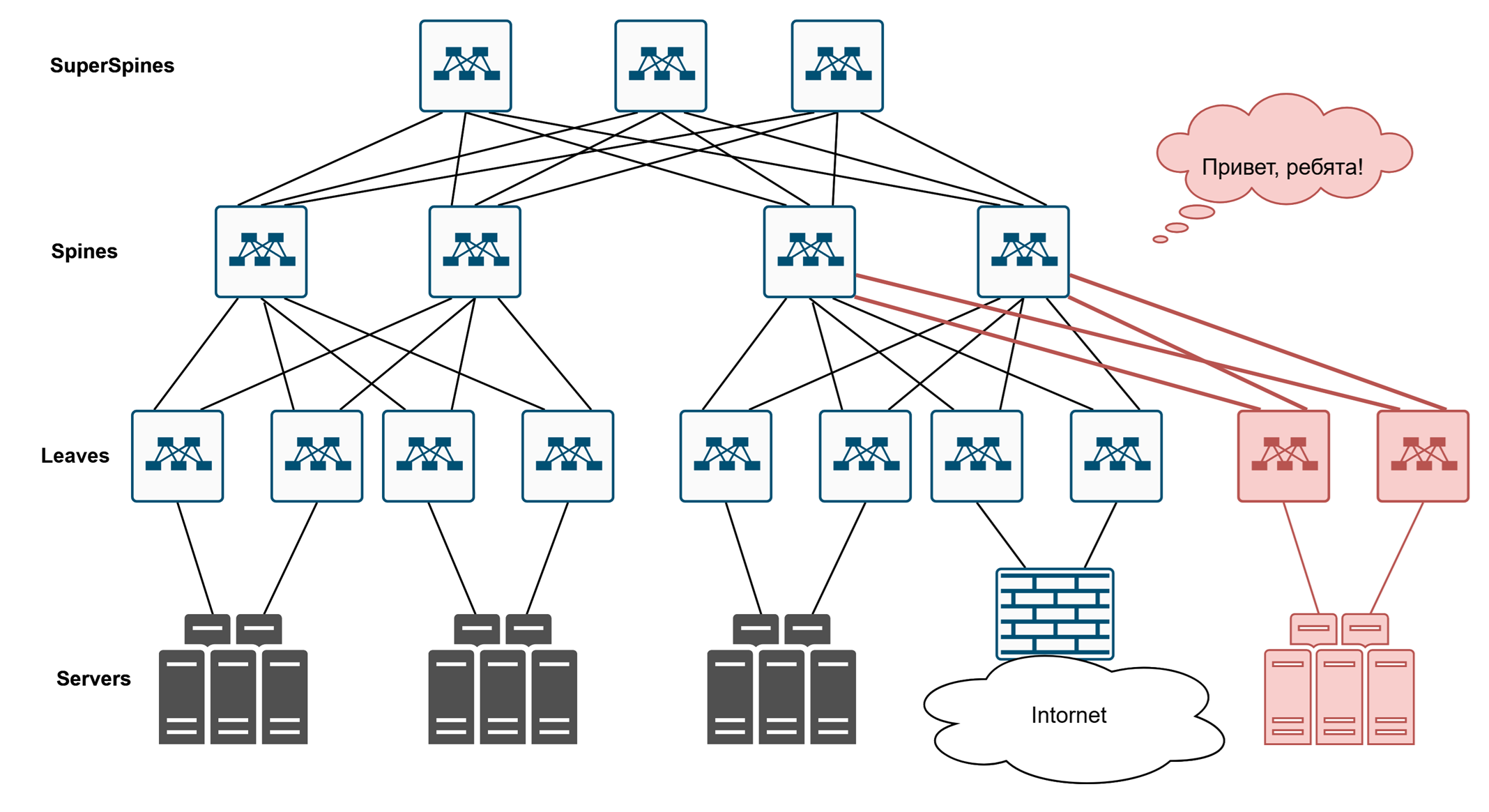
- Второе — это большое количество элементов, которые друг друга дублируют. Это сделано не просто так. Это сделано как раз для отказоустойчивости. Отвалилось там, отвалилось сям — ничего страшного, трафик пойдёт эдак. Отвалился вот этот — тоже ничего страшного. Отвалился этот — и это переживём. Сеть становится отказоустойчивой.
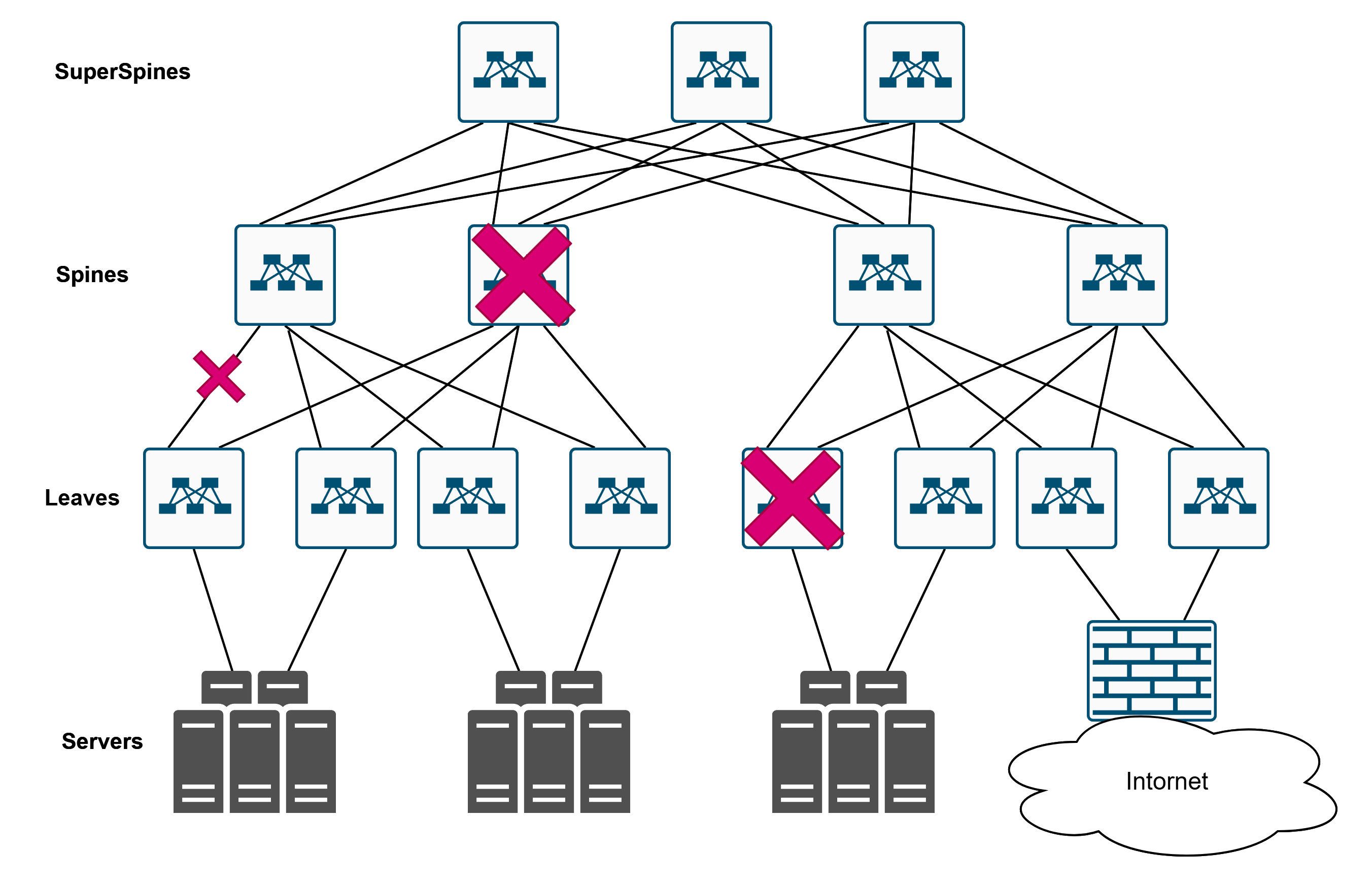
Линки, которые здесь нарисованы, могут утилизироваться одновременно — в этом преимущество. Обычно это какая-то IP-фабрика, где у нас используется протокол динамической маршрутизации, который позволяет использовать несколько путей одновременно, в отличие от какого-нибудь мутный STP, который блокирует линки.
Универсальность. Да, так как это IP-фабрика, поверх этой IP-фабрики могут бегать любые сервисы. Это могут быть разные VPN, там GRE, вы можете запускать разные VXLAN и так далее, и тому подобное. То есть IP-фабрика строится под любой тип сервиса, который уже, например, в виде оверлейной сети может доставлять трафик до конечного сервиса
Часто упоминают некую “экономическую эффективность”, но тут вызывает вопросики, потому что, конечно, это всё надо считать. Пунктик такой спорный.
Ну а вообще, сети сами по себе мало кому интересны — всем важны сервисы, которые они поддерживают. Как сетевые архитекторы и инженеры, мы всегда должны помнить, что людям важны именно сервисы. А чтобы эти сервисы работали, нужны сети. Вот такая простая логика.
А что же нужно сервисам (помимо сети, конечно)? Как ни странно, сервисам нужно всё то же самое.
Лёгкость масштабирования: Например, если мы создаём сайт с котиками и у нас появляется много пользователей, нам нужно добавить ещё один сервер и распределить трафик с помощью балансировки. Инфраструктура должна легко поддерживать это. С увеличением количества пользователей должно расти и количество хранилищ данных, так как хранилище — это тоже сервис, который должен уметь масштабироваться.
Отказоустойчивость: Если мы сделали сайт с котиками, и один сервер вышел из строя, пользователи всё равно должны иметь доступ к своим котикам. Даже если целый дата-центр перестанет работать, пользователь не должен это заметить — ему важны котики.
Эффективное использование ресурсов: Здесь на помощь приходят облачные технологии. Почему облачные вычисления стали популярными? Благодаря гибкости управления ресурсами. Сегодня у вас 10 пользователей, завтра 100, а послезавтра снова 15. Нужно уметь гибко масштабироваться. Для этого используются контейнерные технологии и другие современные облачные решения.
Деплоим сайт с котиками

Итак, если мы решили создать сайт с котиками и хотим, чтобы он был масштабируемым и надёжным, какие шаги нужно предпринять для обеспечения его отказоустойчивости?
- Добавляем пачку серверов с фотографиями котиков
- Делаем отказоустойчивость на уровне датацентра\региона
- Делаем геораспределение по всему миру
- Настраиваем балансировку
- ???
- PROFIT!
Тут начинают возникать вопросики…
Вот, допустим, мы сделали инфраструктуру, которая хостит наших котиков:
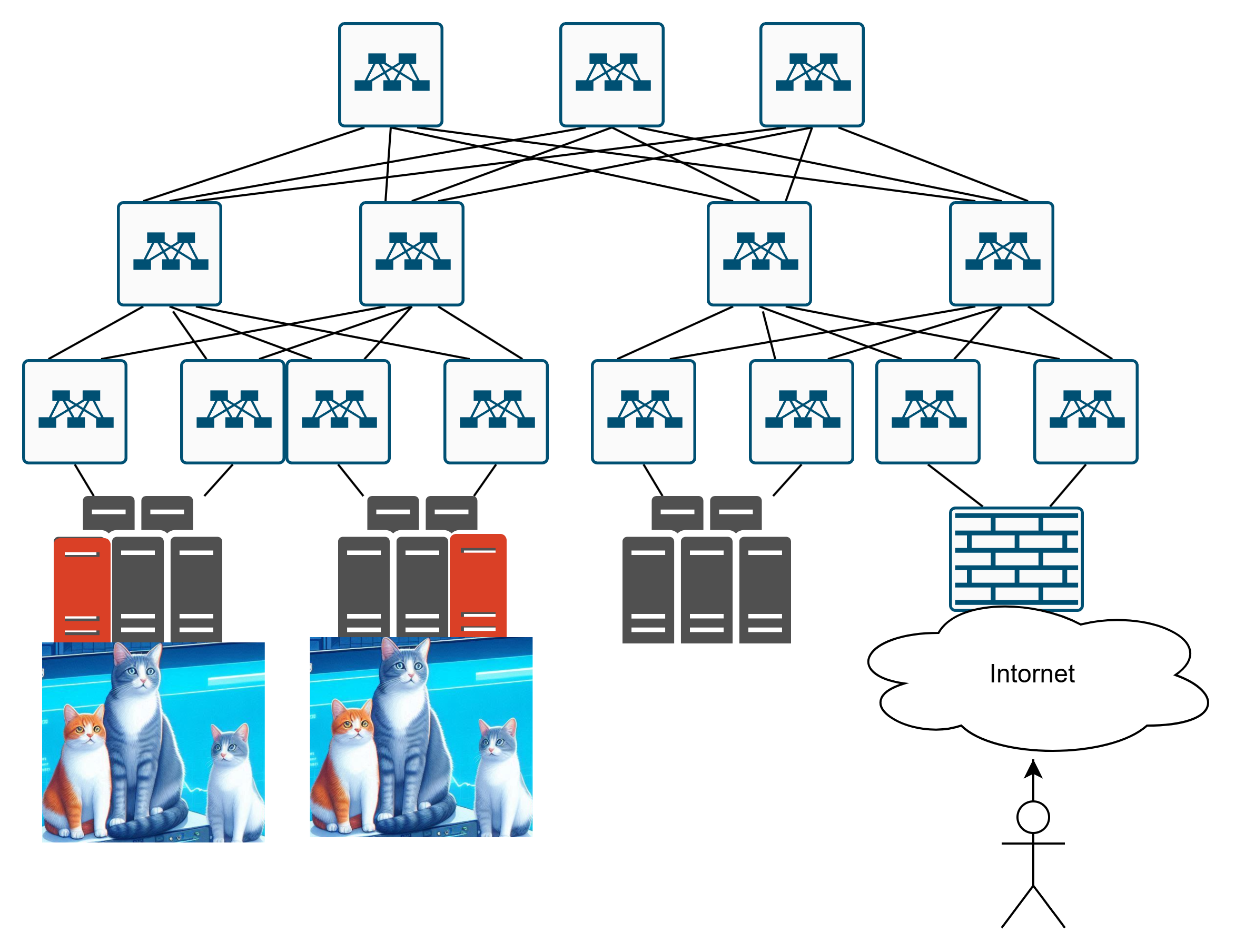
Как пользователю добраться до сайта с котиками если серверов несколько?
Пользователь приходит в датацентр, и чё? Куда ему идти? До этих котиков?
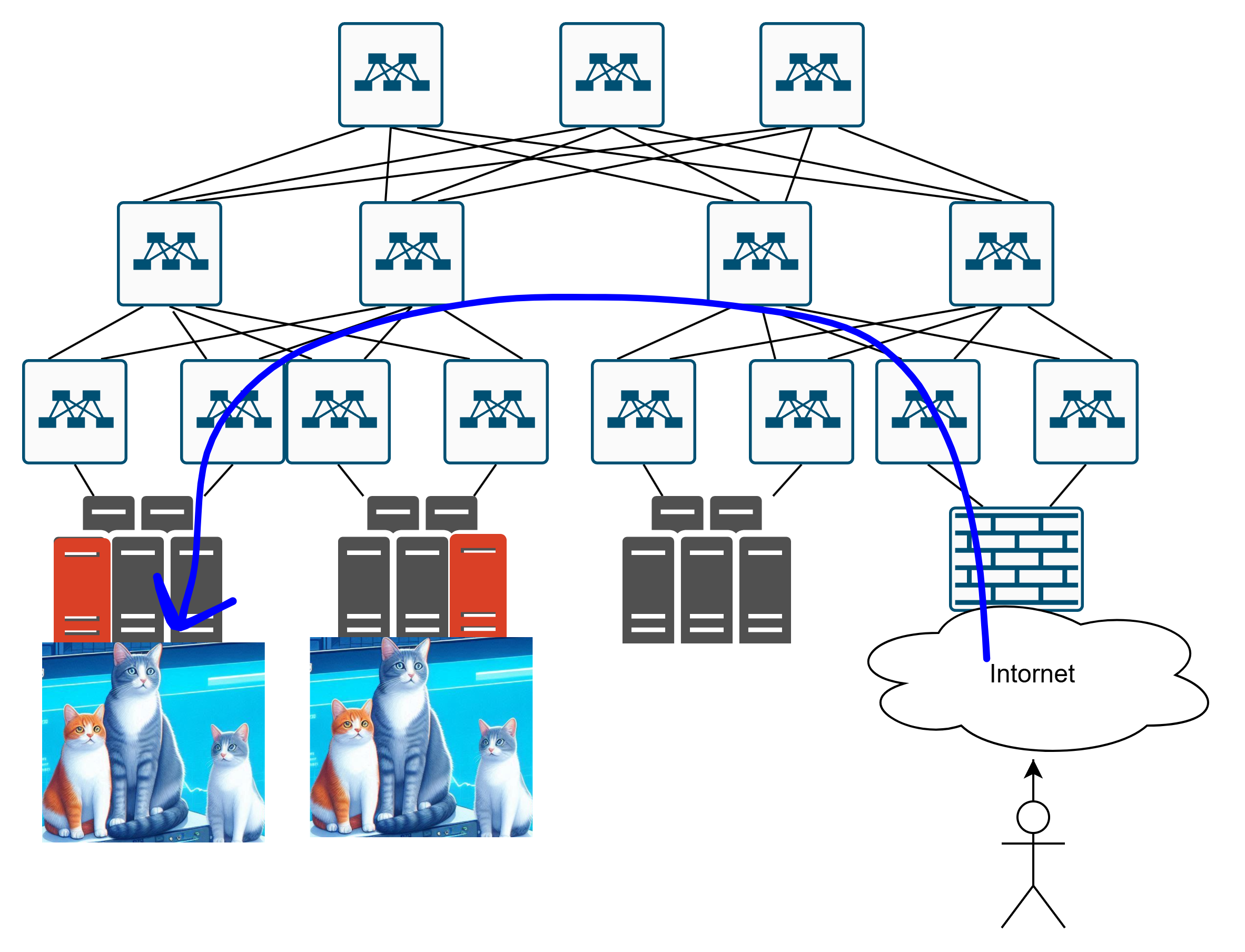
Или до вот этих вот?
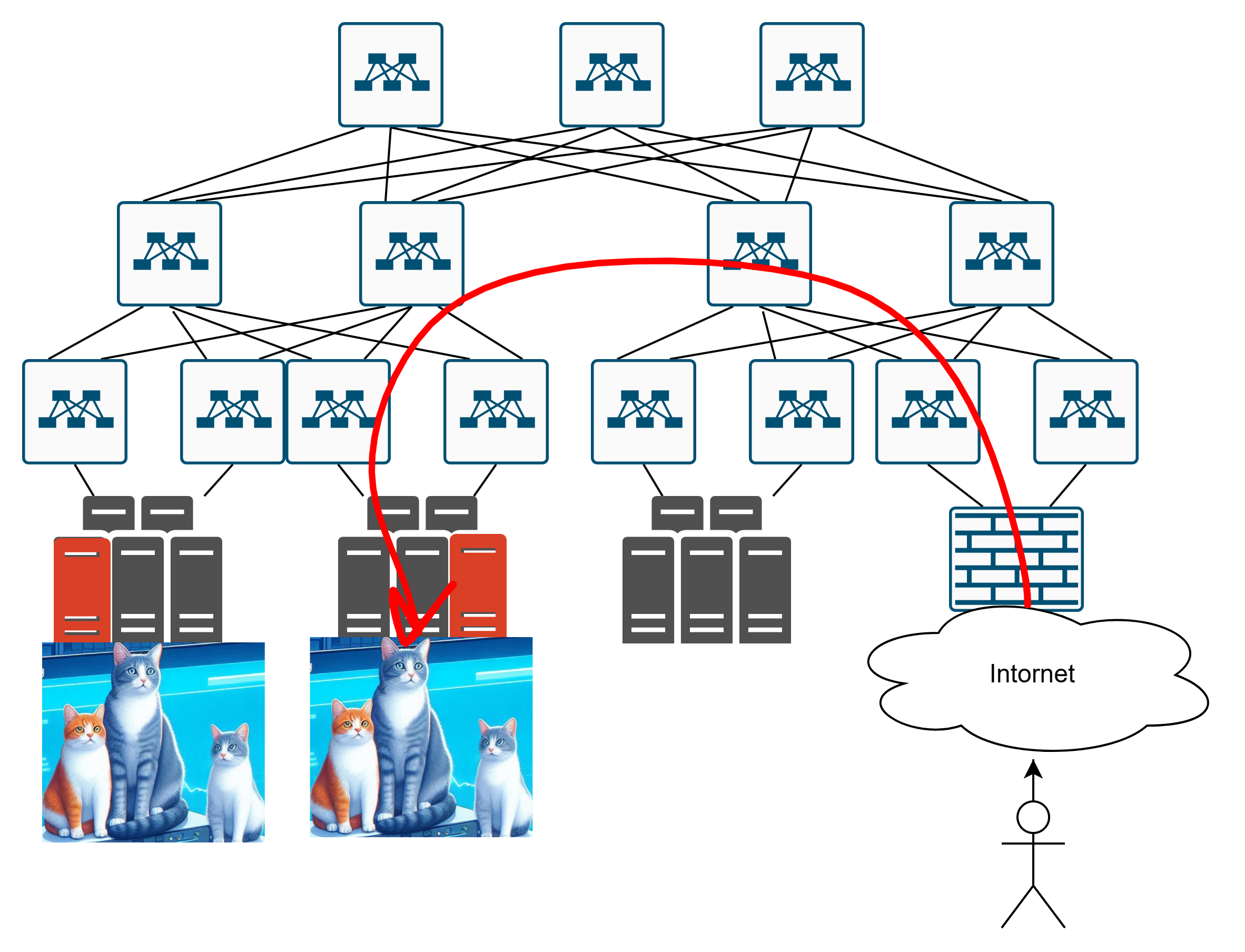
И если до вторых котиков, то как конкретно пробраться туда? Вот так?
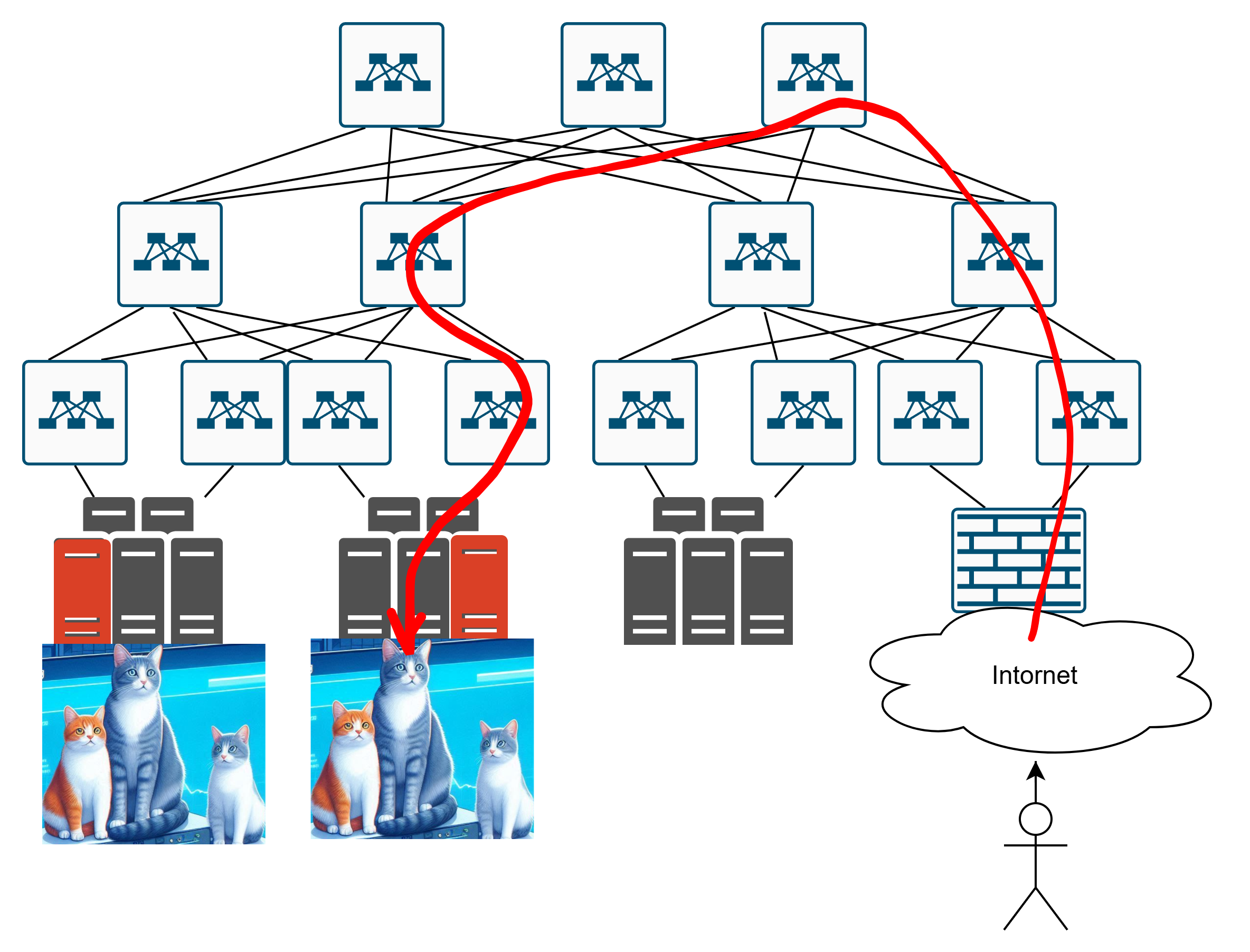
Или вот так вот?
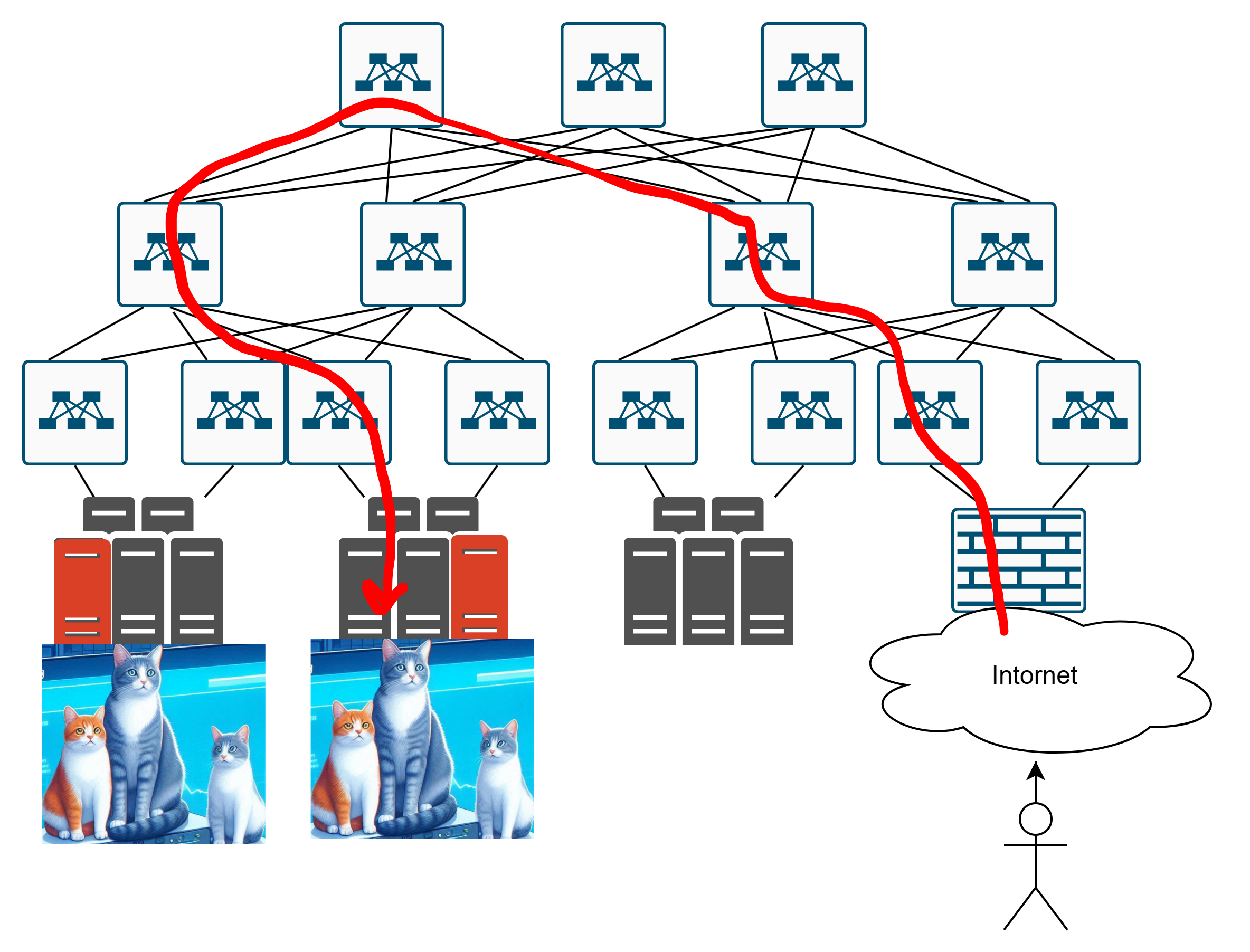
Но допустим, мы эту проблему каким-то образом решили.
Как пользователю добраться до сайта с котиками если датацентров несколько?
Ведь дальше мы начинаем масштабироваться - нам становится тесно в датацентре, ещё и эти стойки по 5КВатт всего. Делаем какой-то мультизональный котиковый сайт. Каждая зона - это датацентр в одном регионе\городе. Какой-то DataCenter Interconnect (DCI) между ними - тёмная оптика, крашенная оптика, L2 VPN, не важно:
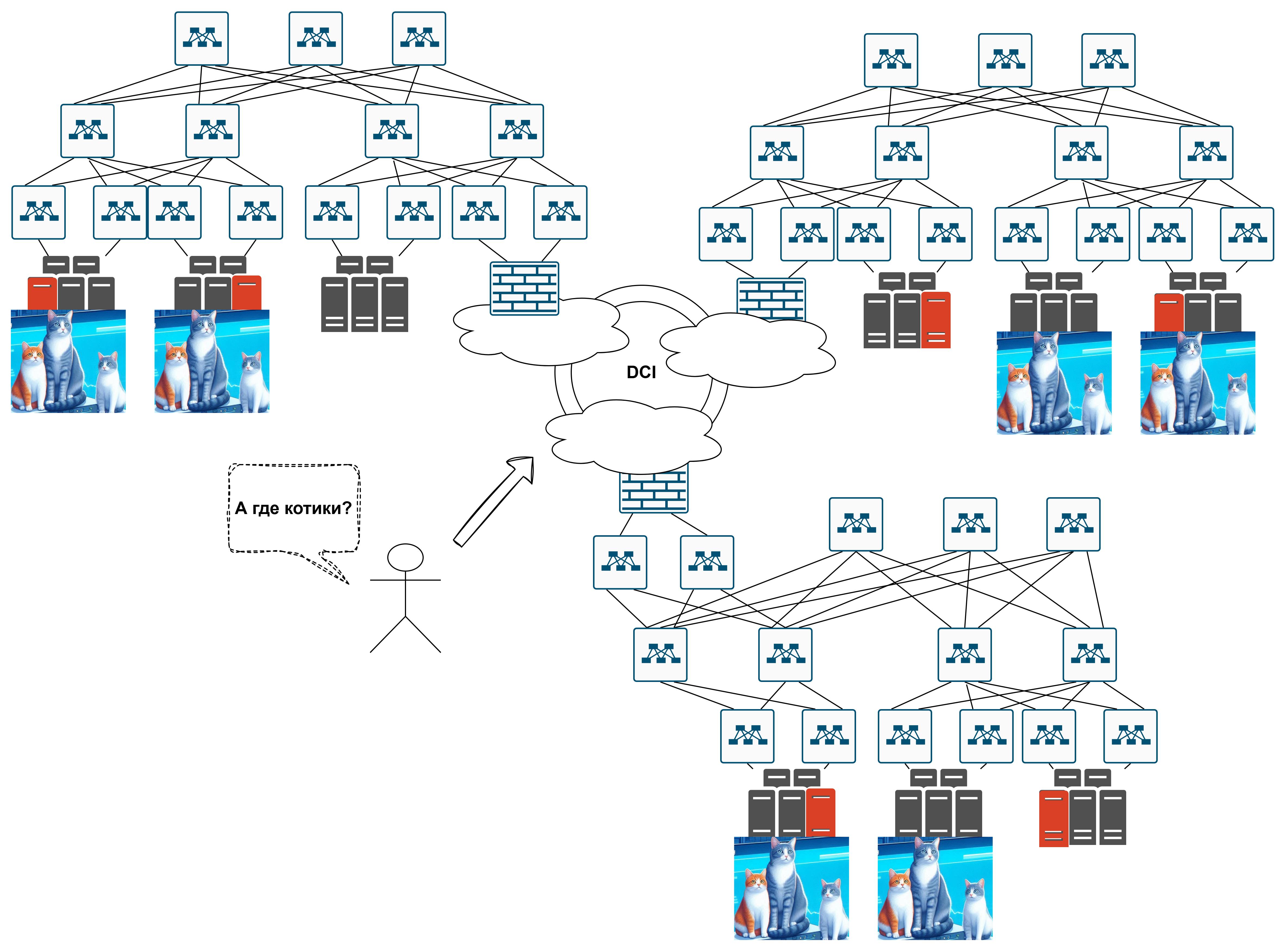
Куди идти за котиками? Непонятно :(
Как пользователю добраться до сайта с котиками если котики разбросаны по миру?
С котиками всегда происходит одно и тоже - они очень популярны! И ваши котики теперь востребованы по всем миру. Нужна мировая экспансия вашего гениального сайта про котиков - делаем регион в Штатах, Европе, Ботсване и, конечно, Магадане!
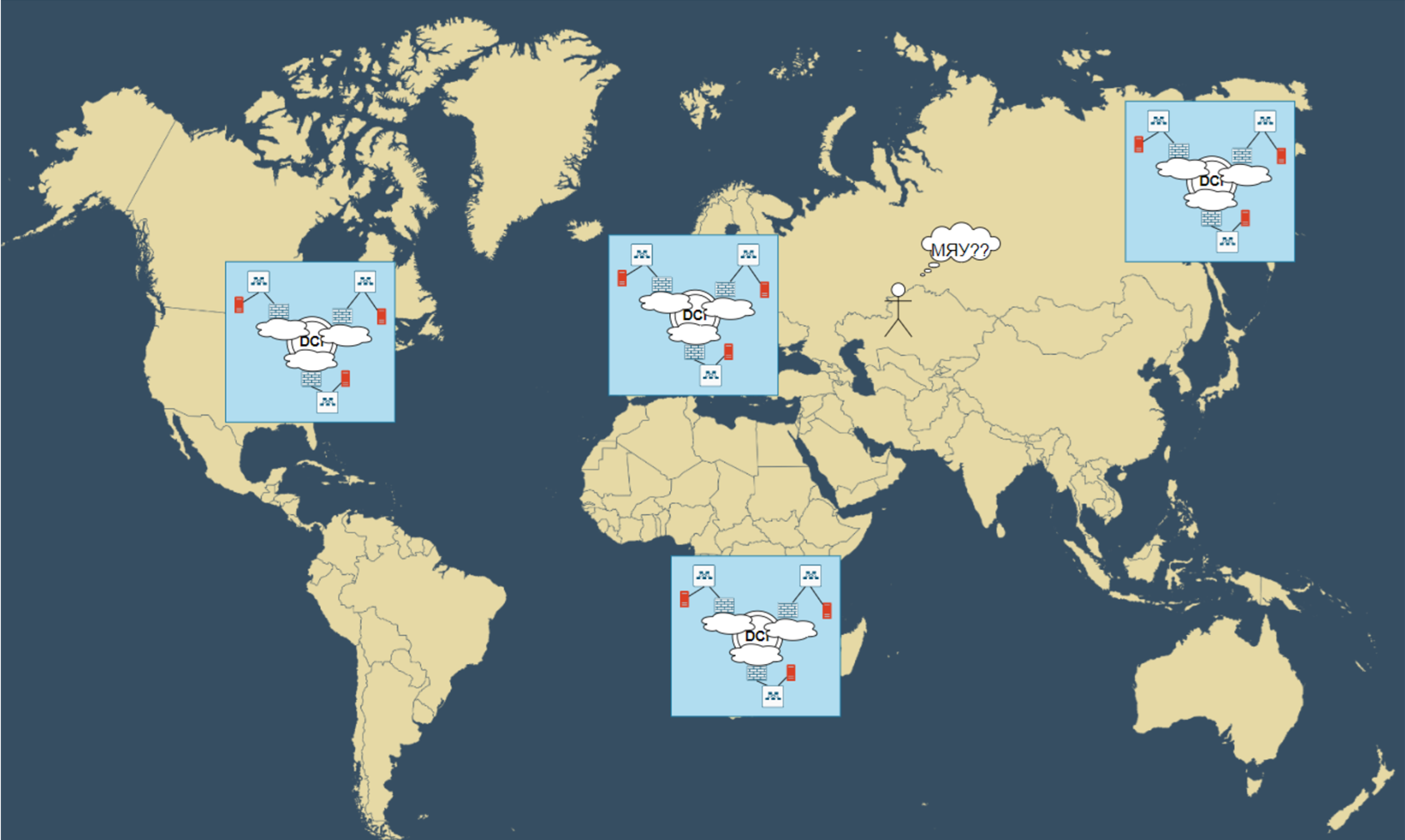
Куда пойти гордому кахазу смотреть котов? А?
Пытаемся решить вопросики
А давайте попробуем попытаться решить возникшие вопросики. Да, как нам трафик то доставить?
В какой регион пригнать трафик пользователя?
Итак у нас есть пользователи в Казахстане, есть сайты с котиками, разбросаные по всему миру. Что собственно можно делать?
Можно вообще не заморачиваться. Просто анонсируем наш публичный IP через BGP без всяких политик и смотрим, что получится. Какая-никакая балансировка всё равно возникнет: часть трафика пойдёт в один дата-центр, часть — в другой. Но если кто хоть раз работал у провайдера или просто шарит, как устроен интернет — говорить тут про ‘оптимальное распределение’ как-то… ну, смешно. Скорее всего, всё перекосит: какие-то дата-центры начнут жрать львиную долю трафика, а остальные так и останутся полупустыми.
Второй вариант — раскидываем IP по миру. Берём четыре адреса: один анонсируем из Штатов, второй — из Европы, ну и из Ботсваны и Магадана тоже. Прописываем их в DNS как 4ре A-записи с одним именем (round-robin сделает своё дело). Плюсы - трафик в теории распределится плюс\минус равномерно между регионами. Минус - DNS-рулетка скорее всего будет стрелять криво, и жителю Ботсваны придётся пиздовать за котиками в Магадан :(
Самый толковый вариант — глобальные балансировщики (GSLB). Это умный DNS, который смотрит откуда клиент и подсовывает ему ближайший дата-центр: Казахстан — Европа, Канада — Штаты. Вроде бы идеально, но на практике всё равно придётся постоянно мониторить и подкручивать — трафик любит течь не туда, куда планировалось. Зато если настроить — будет работать лучше любого round-robin’а. Вот таким образом пользователь, находясь в Казахстане, скорее всего, придёт куда-то в Европу. Находящийся в Канаде, скорее всего, придёт куда-то в США.
В какой датацентр в регионе пригнать трафик?
Теперь нам нужно доставить трафик внутри региона. Здесь в принципе методы балансировки те же самые.
Не делать в принципе ничего — положиться на дикий BGP. Просто анонсируем из дата-центров один и тот же IP и смотрим, что получится) Авось как то разбаланисируется - главное стыки со всякими разными операторами заиметь в разных местах
Второй вариант — снова играем в DNS-рулетку, но уже внутри региона. Раздаём каждому дата-центру свой уникальный /24 и общий резервный /22. Если один ДЦ отвалится — трафик автоматически перекинется на остальные через общую сеть. Работает? Вроде да. Идеально? Ну…
Третий вариант — пусть трафик идёт в любой дата-центр региона, будь то Ховрино или Бутово. Разницы нет — главное, что он в нашей сети. А дальше в дело вступает какой-нибудь MPLS TE: он автоматически раскидает трафик между дата-центрами пропорционально их мощностям. Если в одном ДЦ два рабочих сервера, а в другом один — то первый получит две трети трафика, второй оставшуюся треть. Никакой магии — просто умная система сама поддерживает баланс по количеству активных серваков. Реализация - дело ваше - моё дело предложить гениальную идею xD
В общем, здесь тоже есть варианты и трафик в датацентр мы, допустим, доставили.
До какого сервера доставить трафик внутри датацентра?
А что можно сделать здесь? До какого сервера доставить трафик внутри дата-центра?
Опять таки - не делаем
НИХУЯНИЧЕГО*, а полагаемся на чистый рандом (утрировано) и отработку стандартных механизмов ECMP в фабрике, используя anycast - все сервера доступны по одному и тому же IP. Однако есть нюанс- если сервис сдох, а сервер ещё дышит и рассказывает об этом в сеть, трафик будет проливаться в чёрную дыру. Никакой проверки состояния живости сервисов нету :(*Но да, если у вас в фабрике BGP - ECMP, скорее всего, придётся включить и слегка подтюнить )
Добавляем немного мозгов балансировке - ставим какой-нить L3\L4 балансировщик. Самое дешёвое что приходит в голову - базовый модуль ядра Linux под названием IPVS с базовыми keepalived-проверками. Теперь нам хотябы понятно, кто реально жив и готов принять трафик, а кто просто машет из гроба своим IP-адресом. Мозгов хоть и добавили, но всё равно балансировка туповата - оперируем только IP и портами, а что внутри пакетов — не понятно.
Добавляем к пункту 2 какой-то Application балансировщик. Вот тут уже настоящая магия: NGINX или HAProxy ковыряются в HTTP-трафике. Хочешь — раскидывай запросы по URL (/cats — на один кластер, /dogs — на другой). Хочешь — привязывай пользователей к серверам через куки. SSL? Оффлоадим прямо тут! - бекенду и так хватает проблем. Минус один - всё это надо уметь готовить )
Идеальная иерархия балансировки в дата-центре
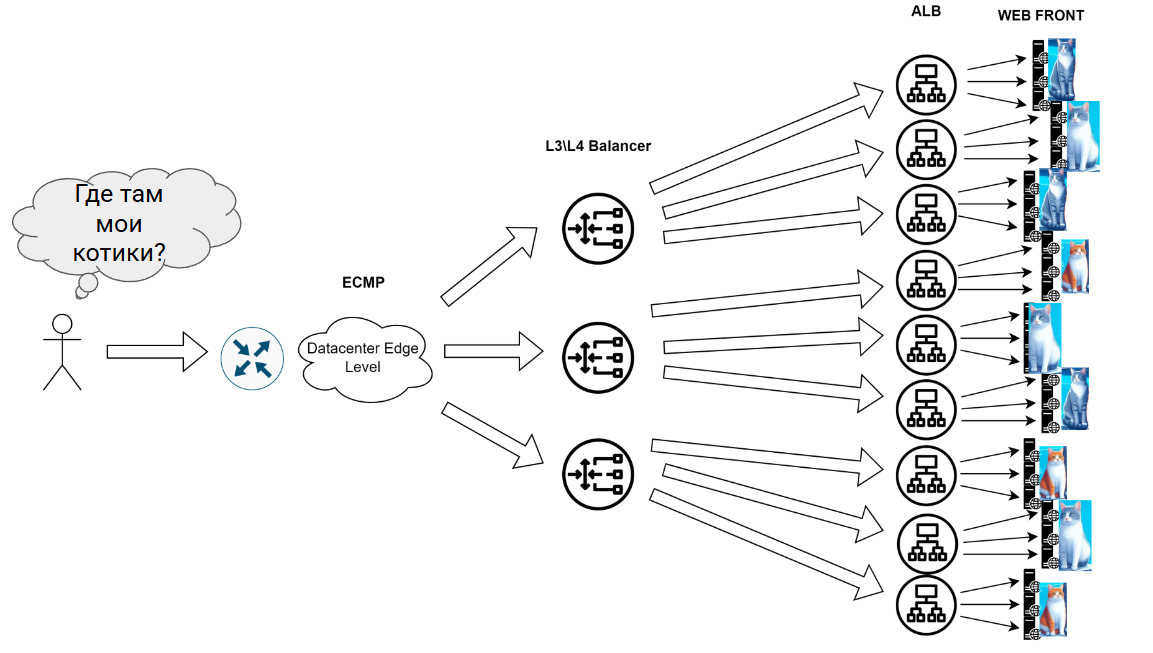
1. Входная дверь (ECMP + Anycast)
Трафик пользователя залетает в фабрику через обычный IP-роутинг. ECMP раскидывает его по L3/L4 балансировщикам (NLB) по простому советскому роутингу. Anycast позволяет всем NLB отвечать с одного IP. Просто и эффективно, но без мозгов.
2. Среднее звено (L4 → L7)
Здесь начинается магия:
- NLB (L3/L4) принимает трафик и строит туннель (GRE/IPIP) до ALB
- Проверяет здоровье сервисов через health checks
- Может использовать DSR для обратного трафика (пакеты идут в обход NLB)
- Распределяет нагрузку между кучей Application LB
3. Финиш (L7-балансировка)
ALB работают с прикладным уровнем:
- Разбирают HTTP/HTTPS как заправские криптоаналитики
- Маршрутизируют по URL (/cats → cluster1, /dogs → cluster2)
- Оффлоадят SSL
- Поддерживают sticky sessions через куки
И это хорошо
- Гибкая масштабируемость: можно добавлять слои NLB/ALB
- Оптимальный путь: DSR сокращает нагрузку на NLB для обратного трафика
- Фатальные ограничения: упрётесь только в физику (провода, мощность серверов)
Масштабируем!
1. Городской уровень (Бутово, Щукино и др.)
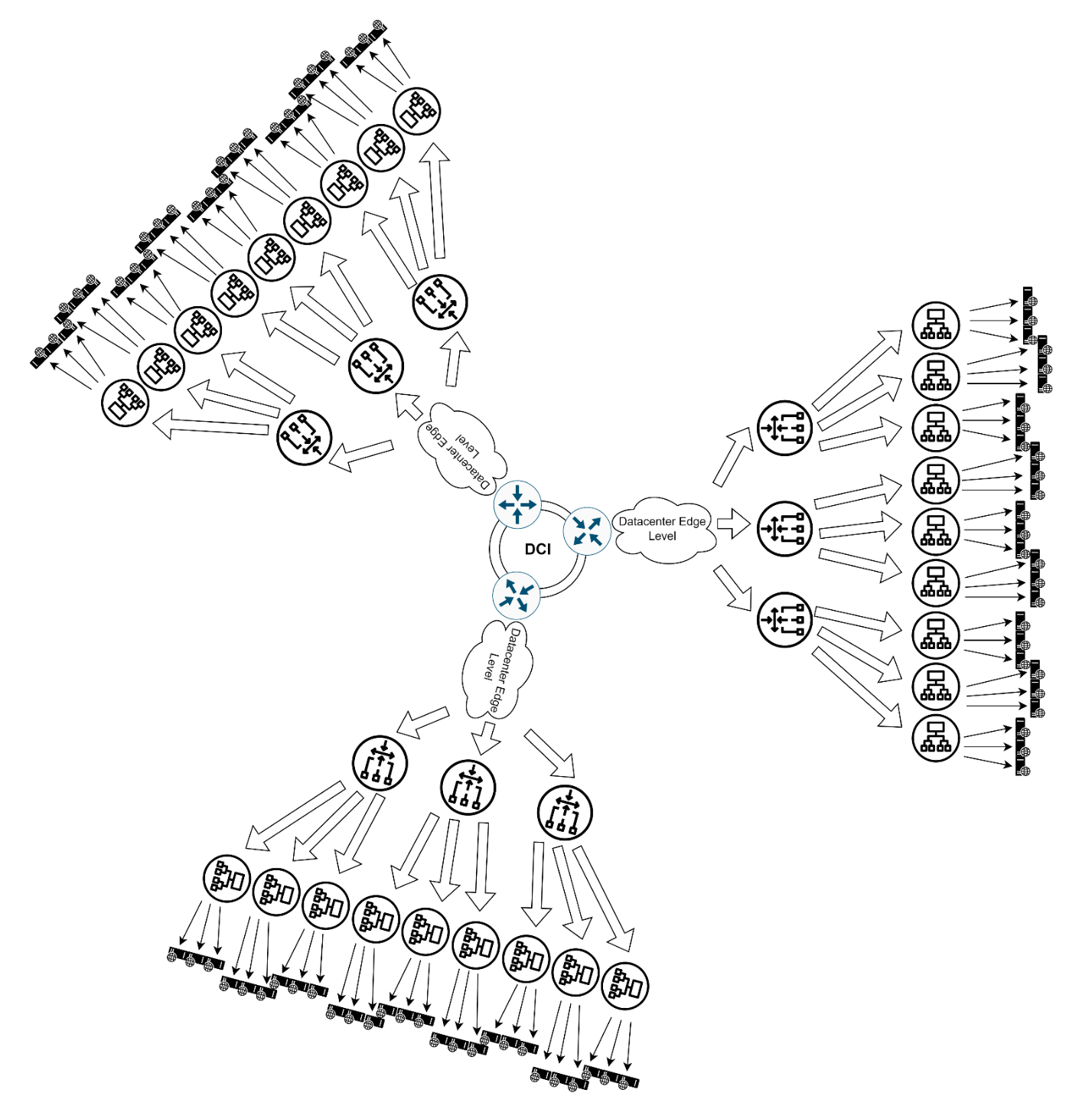
Когда одного дата-центра мало, добавляем региональную балансировку - множим датацентры, добавляя чуточку логики на уровне DCI (или не добавляю)
2. Международный уровень
Когда городом не ограничиваемся:
- Континентальные точки присутствия (Европа, Азия, США)
- Тот же принцип, но с доп. слоями:
- Гео-DNS (клиент из Берлина получает IP франкфуртского ДЦ)
- Межконтинентальные Anycast (BGP + локализованные anycast-IP)
- Глобальный GSLB с учётом:
- Задержек между континентами
- Юридических ограничений (GDPR в ЕС)
- Цены на транзит в регионе
“Это. Просто. Охуенно.” (с) Анонимный сетевой инженер
Примеры балансировщиков

L7 (Application Load Balancers)
- Nginx
- HAProxy
- Traefik
- Envoy
- Istio (Service Mesh)
L3/L4 (Network Balancers)
- IPVS (LVS)
- F5 BIG-IP
Облачные решения
- AWS ALB
- GCP HTTP(S) LB
- Azure Application Gateway
Дальше была идея сделать небольшое практическое “демо” как сделать простейшую балансировку в лабе с помощью ECMP+Anycast+Linux IPVS, но мне лень. Делайте сами.
Проблемы и вопросы сетевой (ECMP) балансировки
Дальше напишу немножко про НЮАНСИКИ которые стоит помнить при работе с ECMP
ЖУТКИЙ ДИСКЛЕЙМЕР. ЛУЧШЕ НЕ РАСКРЫВАЙТЕ
Я НЕ ХОТЕЛ, ТАК ПОЛУЧИЛОСЬ. Где-то на подкорке отложилось. В общем, изложение своими словами получилось со знатной долей чудной отсебятины
Кто кандидат на равнозначность?
А как вообще включить эту самую ECMP, как маршрутам попасть в группу счастливчиков? Требований не много на самом деле
Оборудование должно поддерживать ECMP в принципе. Наверное мало кто НЕ поддерживает в 2025-м то.
Маршруты должны быть из одного протокола маршрутизации. При этом протокол маршрутизации должен поддерживать multipath. Ну стоит помнить что например у OSPF\ISIS - это дефолтная опция, а у BGP - не всегда*
Маршруты должны иметь одинаковую стоимость с точки зрения протокола.
BGP “со звёздочкой”, потому что не везде multipath для него включен, ну и в кейсах когда у вас eBGP в фабрике стоит помнить про bgp multipath as-path relax
Куда пакет-то отправлять?
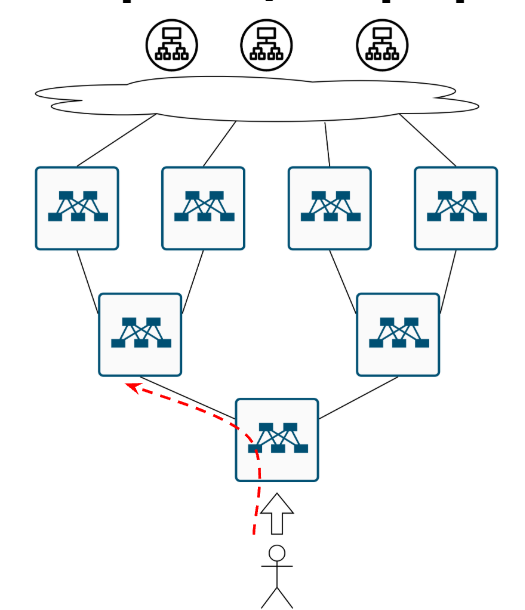
Ок, ну допустим ECMP мы включили-настроили, и вот в такой схеме у нас два возможных пути:
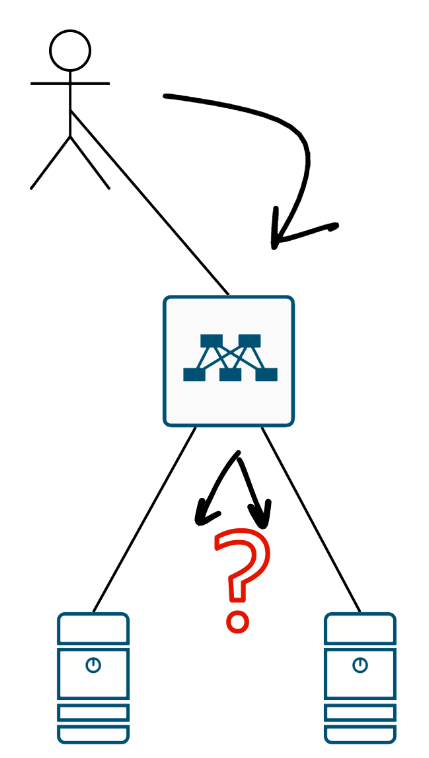
И чё?
Когда перед коммутатором два “равнозначных” пути, возникает ключевой вопрос: по какому принципу распределять трафик? Варианта два — оба с подводными камнями.
Варианта по-сути два:
1) Per-packet. Каждый пакет по round-robin раскладывается то в один порт, то в другой.
И для некоторых кейсов это может быть даже ок:
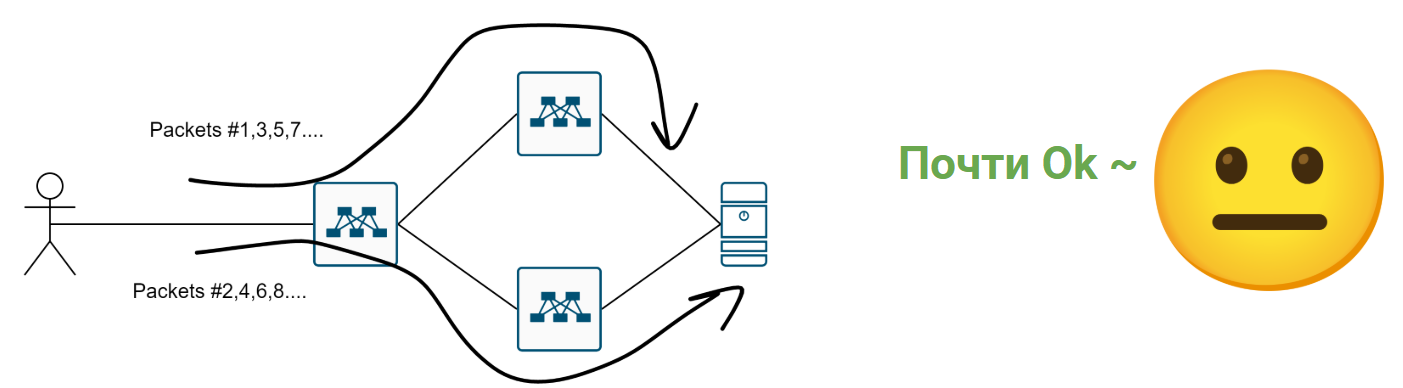
Но как только придёт TCP ANYCAST…
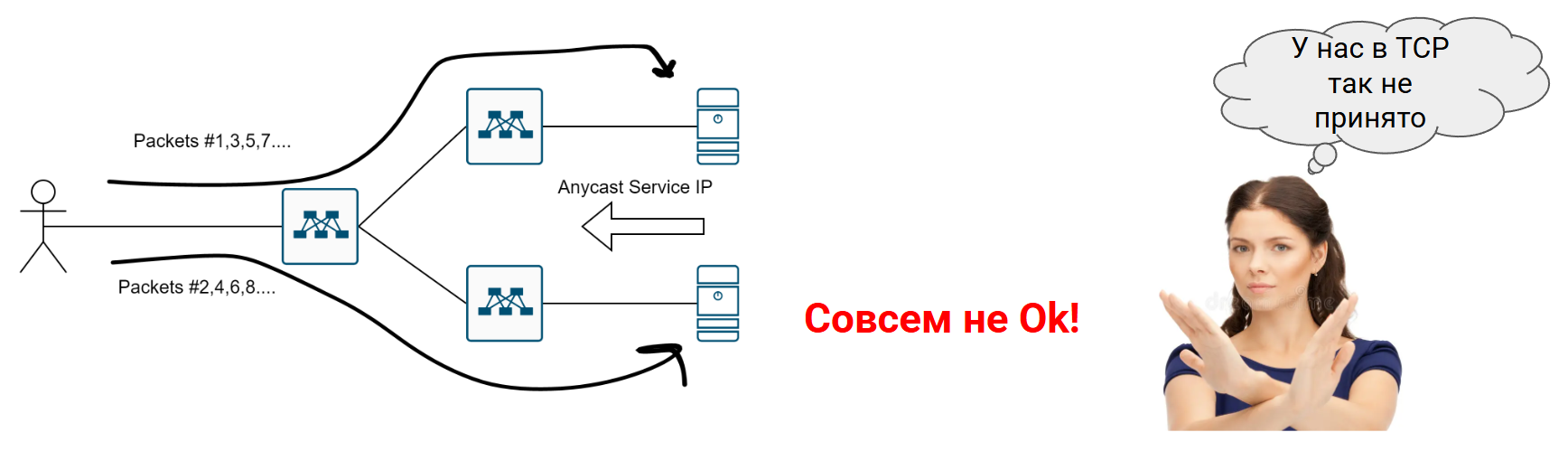
Потому норм пацаны юзают вариант два
2) Per-flow. Считается хеш от параметров потока:
- MAC-addresses + EtherType для L2
- 5 tuple для udp\tcp
То есть у нас вот по такой простой картинке считается некий Хеш:
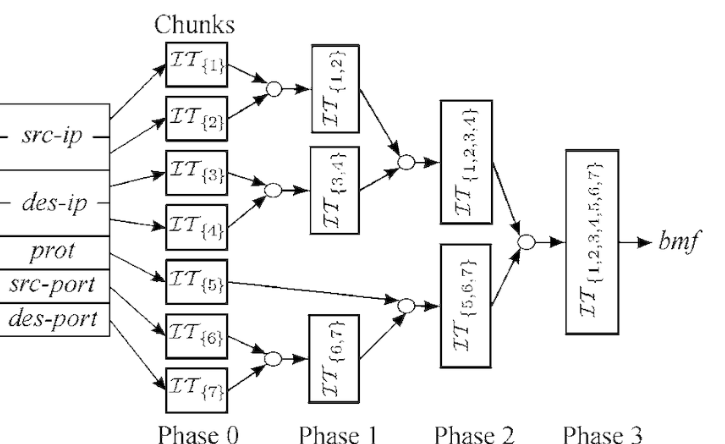
Этому хешу ставится в соответствие некий выходной порт. Дальше приходит пакетик, для него ещё раз считается хеш и если параметры потока не поменялись - хеш получается тот же самый, а у нас уже есть для него выходной интерфейс - ну туда его и отправим. А если про поток ничего не известно было заранее - отправим в новый порт и в табличку запишем. В итоге трафик в рамках одной и тойже tcp сессии. Будет всегда идти в один и тот же интерфейс… Ну как “всегда”…
Вот есть у нас девственно чистая безпоточная сеточка:
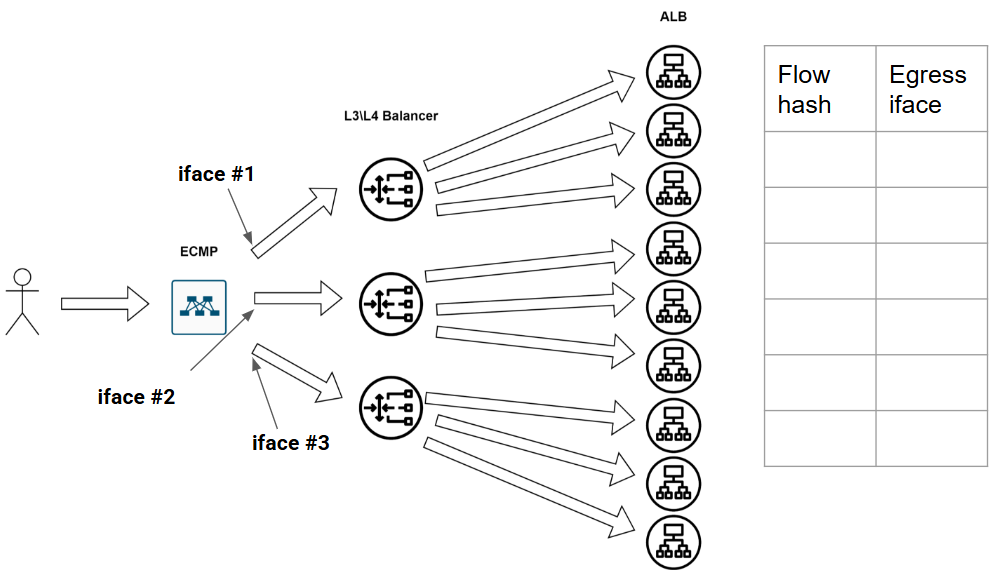
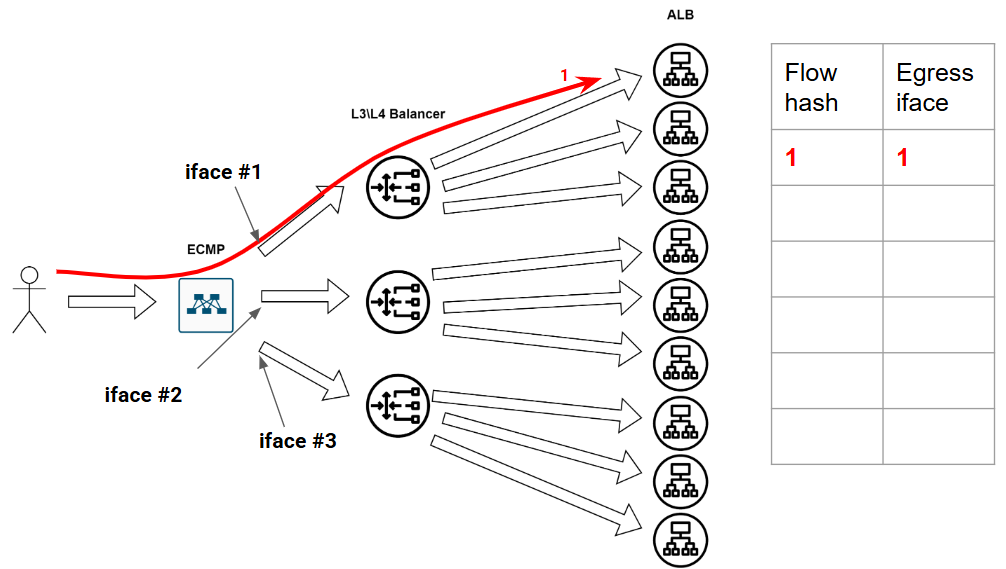
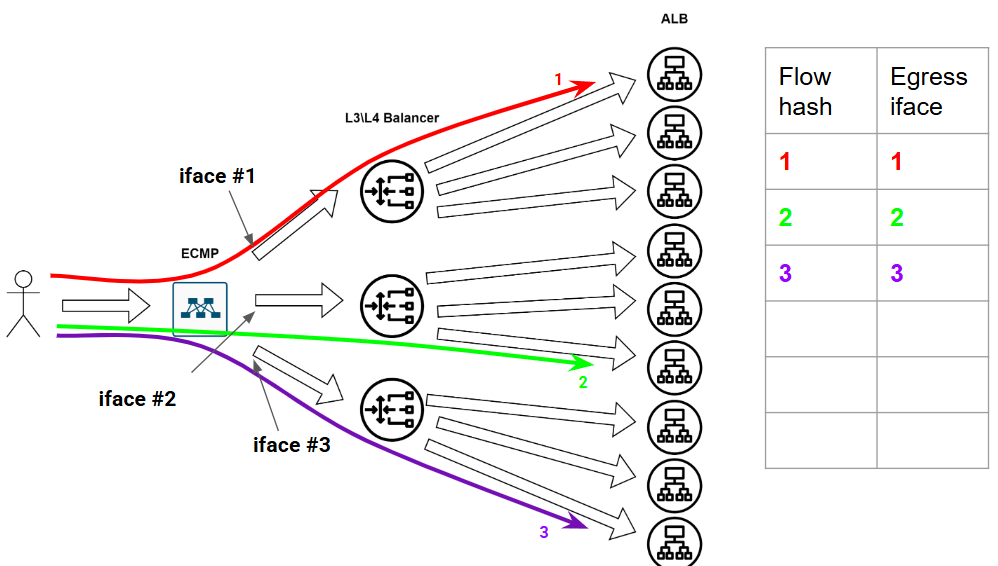
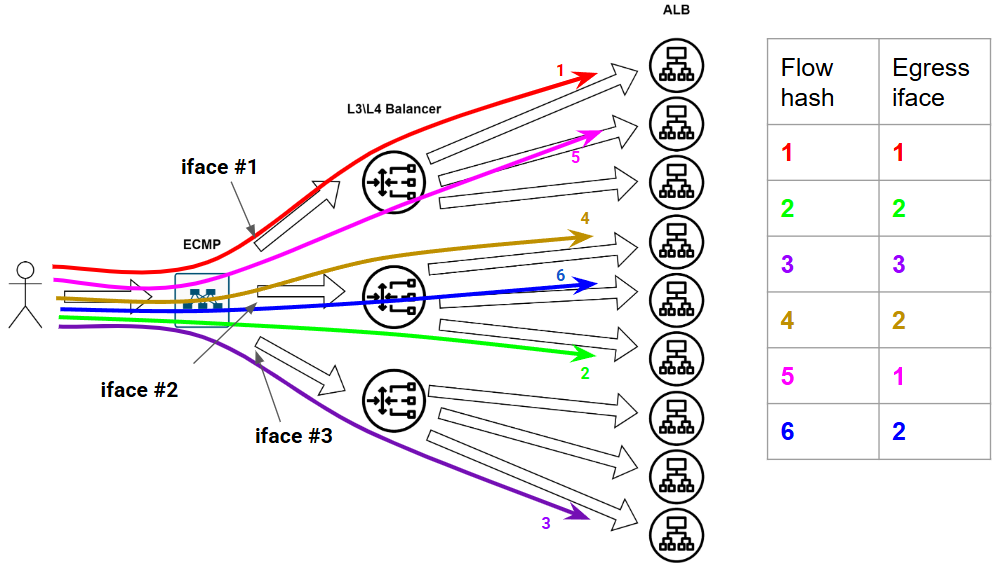
Казалось бы, что может пойти не так? Может, например, какая-нибудь фигня произойти в сети. А фигни в сети происходят постоянно - это норма. Ну в общем, потерялся вот у нас один балансровщик из сети - сломался малый. Так у нас вся эта наша табличка по пизде пойдёт - ПОРТ ВЫПАЛ ИЗ БАЛАНСИРОВКИ, АААА, МИР ПЕРЕВЕРНУЛСЯ, СРОЧНО ВСЁ ПЕРЕСЧИТАТЬ.
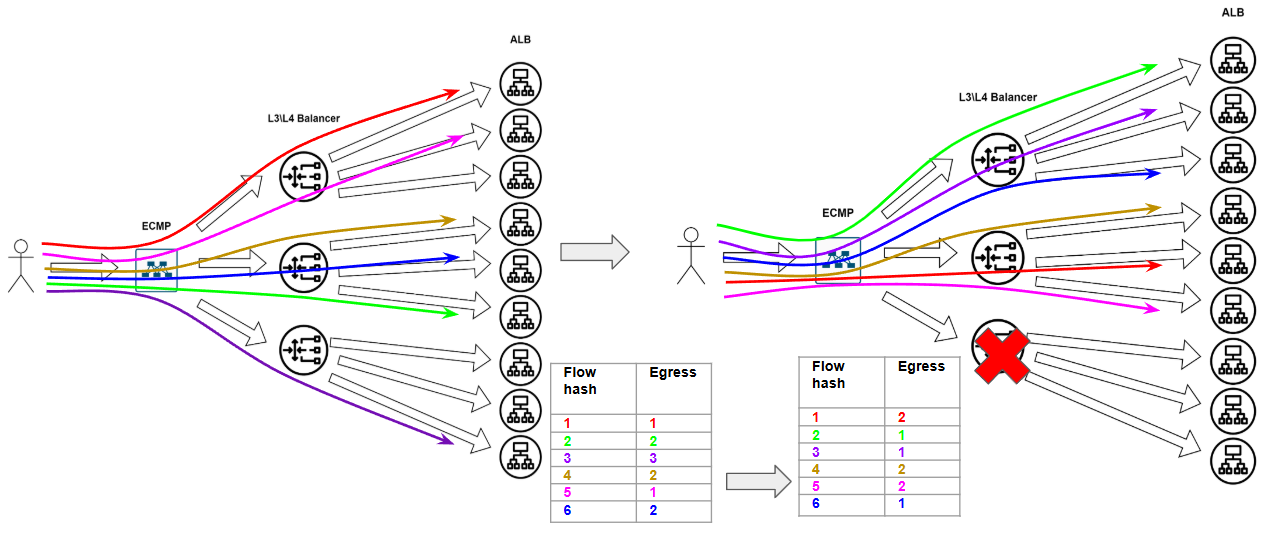
Resilient Hashing
В целом, умные дядьки давно уже всё придумали и обозвали это “неунывыющий хэшинг”. Подробно наверное, можно почитаться вот туть - https://docs.nvidia.com/networking-ethernet-software/cumulus-linux-41/Layer-3/Equal-Cost-Multipath-Load-Sharing-Hardware-ECMP/ Я немного вкратце скажу про это, своровав картинки оттуда же. Итак, вот произошёл у нас такой кейс, было 4-ре выходных интерфейса, один сломался:
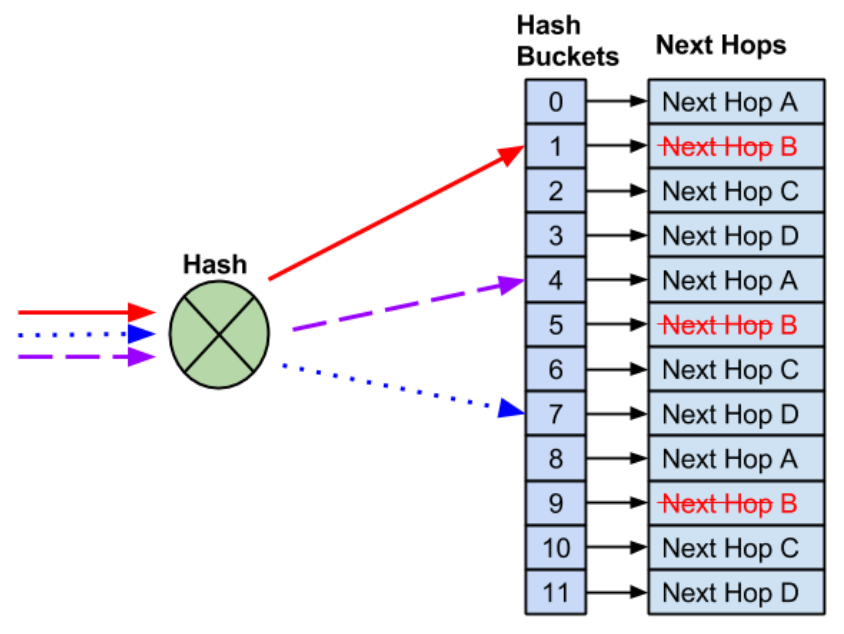
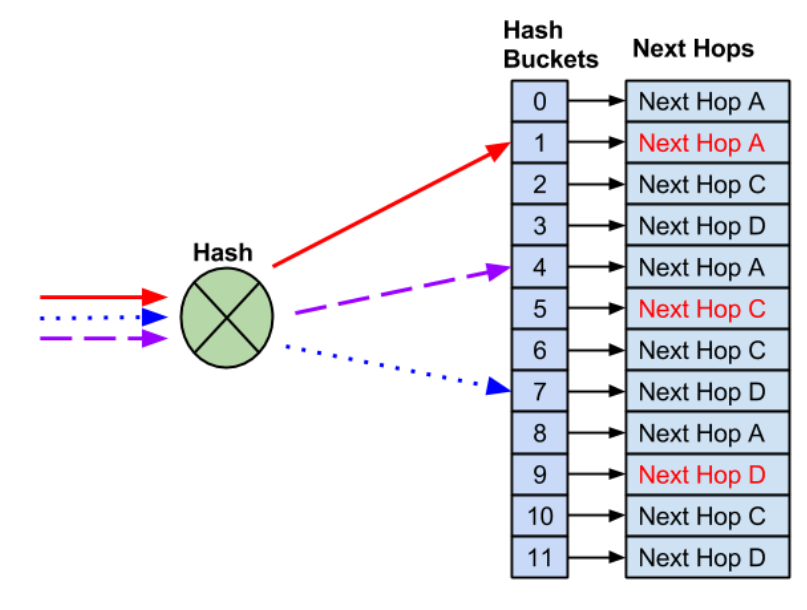
Итоге - рабочее не ломаем, сломавшееся чиним. Занятно, но проблема становится более “проблемной” когда речь не про сломавшийся путь, а про новый next-hop, который надо вклинить в табличку, расталкав существующие потоки:
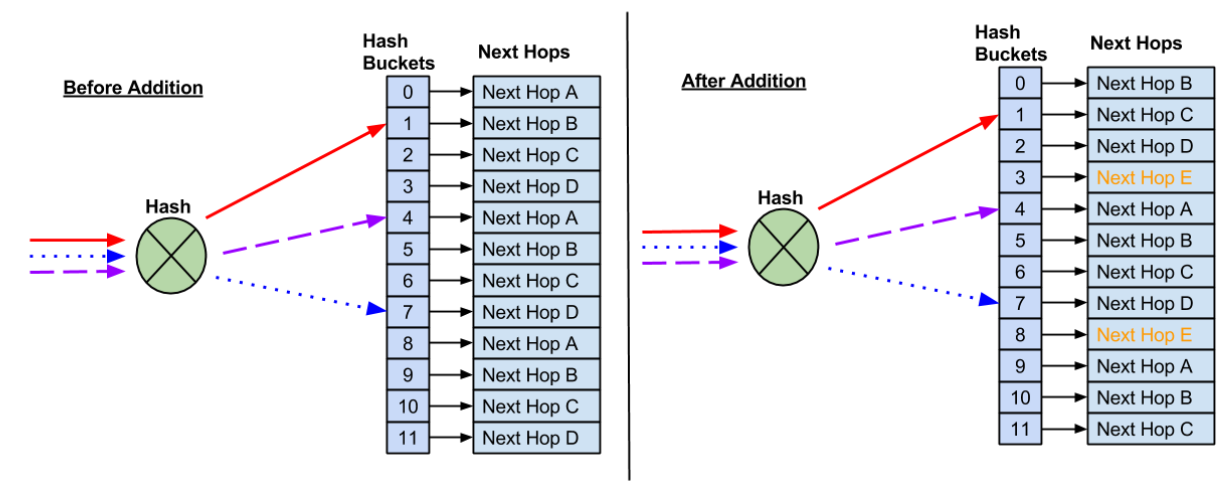
То есть появление нового балансировщика привносит больше проблем чем сломанный старый! В общем, будьте аккуратней, ребята, не деплойте новые балансировщики в ЧНН и избегайте флапов!)
Поляризация трафика
Ещё одна вещичка, про которую уже все забыли. Обычно, фабрику строят на оборудовании одного и того же вендора, и даже если это разные железки, логика расчёта хеша и сопоставление хеша некст-хопу может быть одинаковая. Поэтому вполне вероятен такой кейс. Приходит, значит поток на нижний коммутатор и по ECMP раскладывается влево:
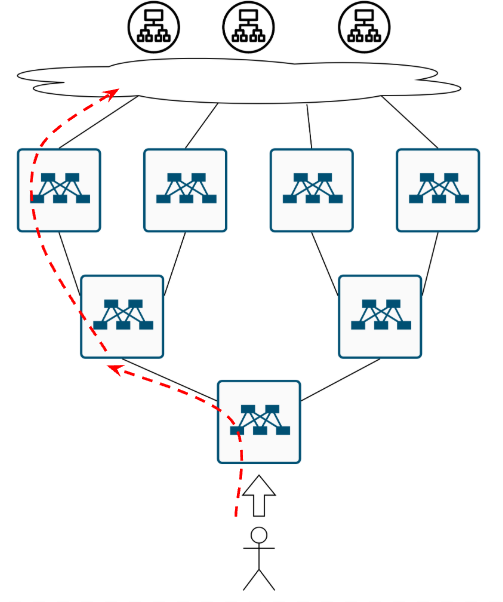
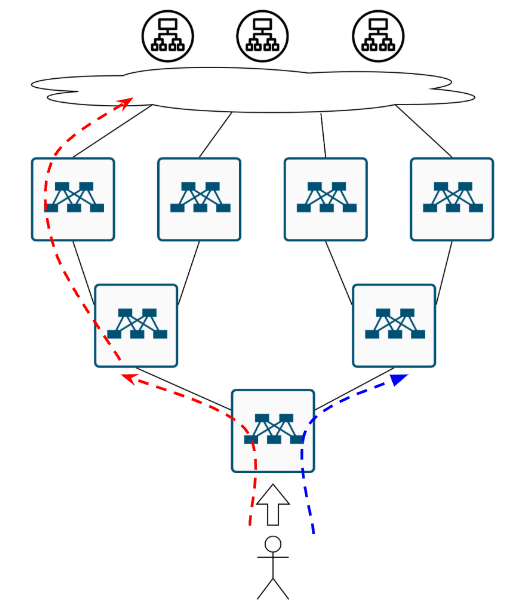
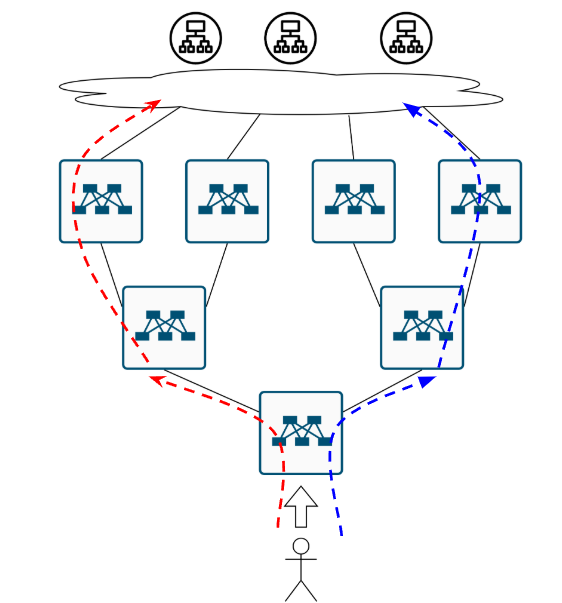
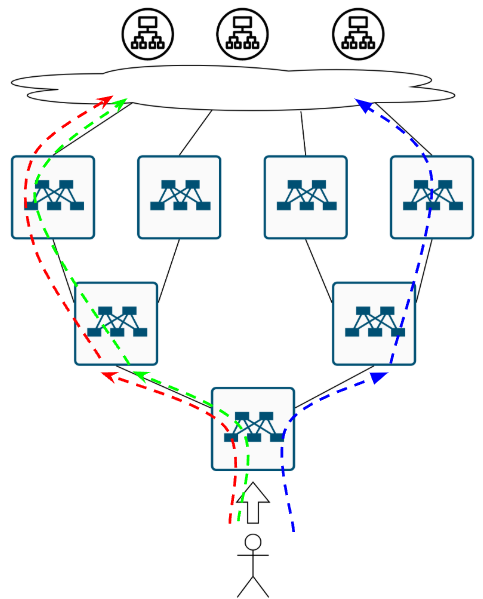
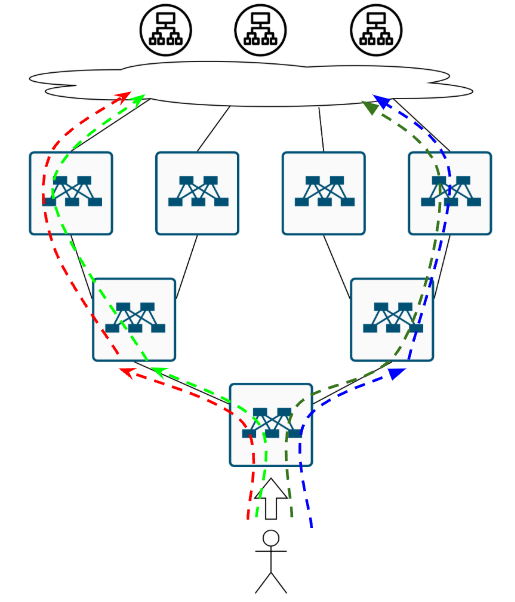
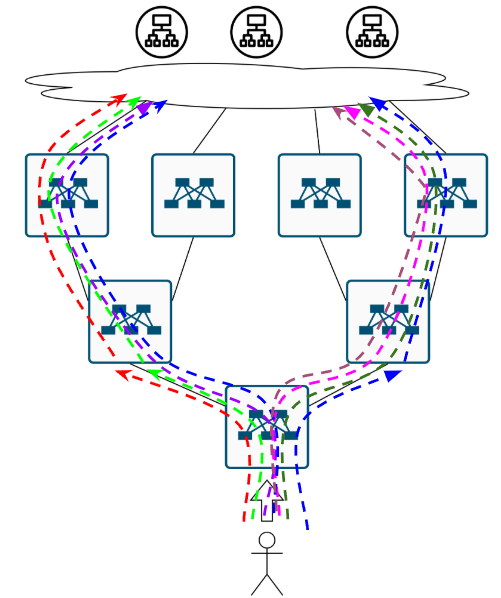
Пахнуло ПОЛЯРИЗАЦИЕЙ. Ну а для решения проблемы с неприятным запахом нужна простая советская…

И последнее.
Когда мы наконец решили проблемы с правильным хешированием и распределением наших потоков и посыпали всё солью, решив проблему поляризации приходят они….

…снова.
Кто-кто?
Мыши, говорю (mouse flows):
Это короткие, небольшие по объему потоки данных, которые обычно состоят из небольшого количества пакетов. Они часто представляют собой запросы и ответы, такие как веб-запросы или небольшие транзакции. Эти потоки чувствительны к задержкам, поэтому важно, чтобы они обрабатывались быстро и с минимальными задержками.
И слоны (elephant flows):
Это длинные, большие по объему потоки данных, которые могут занимать значительную часть пропускной способности сети. Они обычно состоят из большого количества пакетов и могут представлять такие задачи, как передача больших файлов или резервное копирование данных. Эти потоки могут создавать заторы в сети, если их не обрабатывать должным образом.
Почему это вообще проблема?
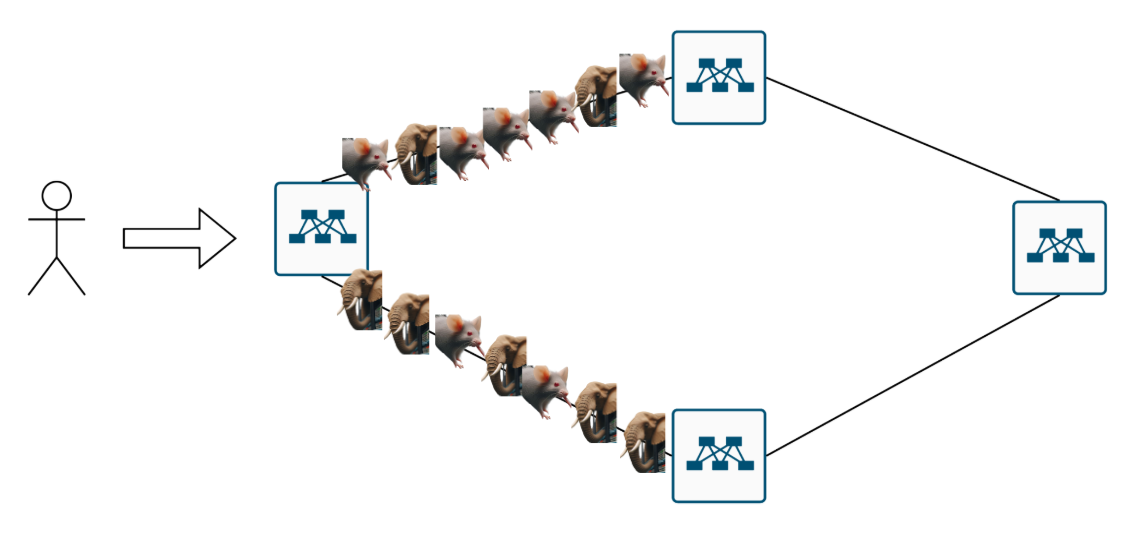
(и тут я понимаю что пора научится делать GIF-ки) В общем, смотрим за картинками, опять. Первой пришла мышка. Отправили её вверх.
В итоге слонов и мышей набежало так, что по количеству потоков мы, кажется, линки нагрузили равномерно, но вот по “тяжести” потоков
Как же усмирить слонов и не раздавить мышей?
Вводим новый термин - flowlet и балансируем по ним!
Flowlet — это “кусочек” TCP-потока, разделённый естественными паузами (например, пока клиент обрабатывает данные и не выслал ACK) от друших таких же кусочков. В общем иногда, TCP ничего не делает )
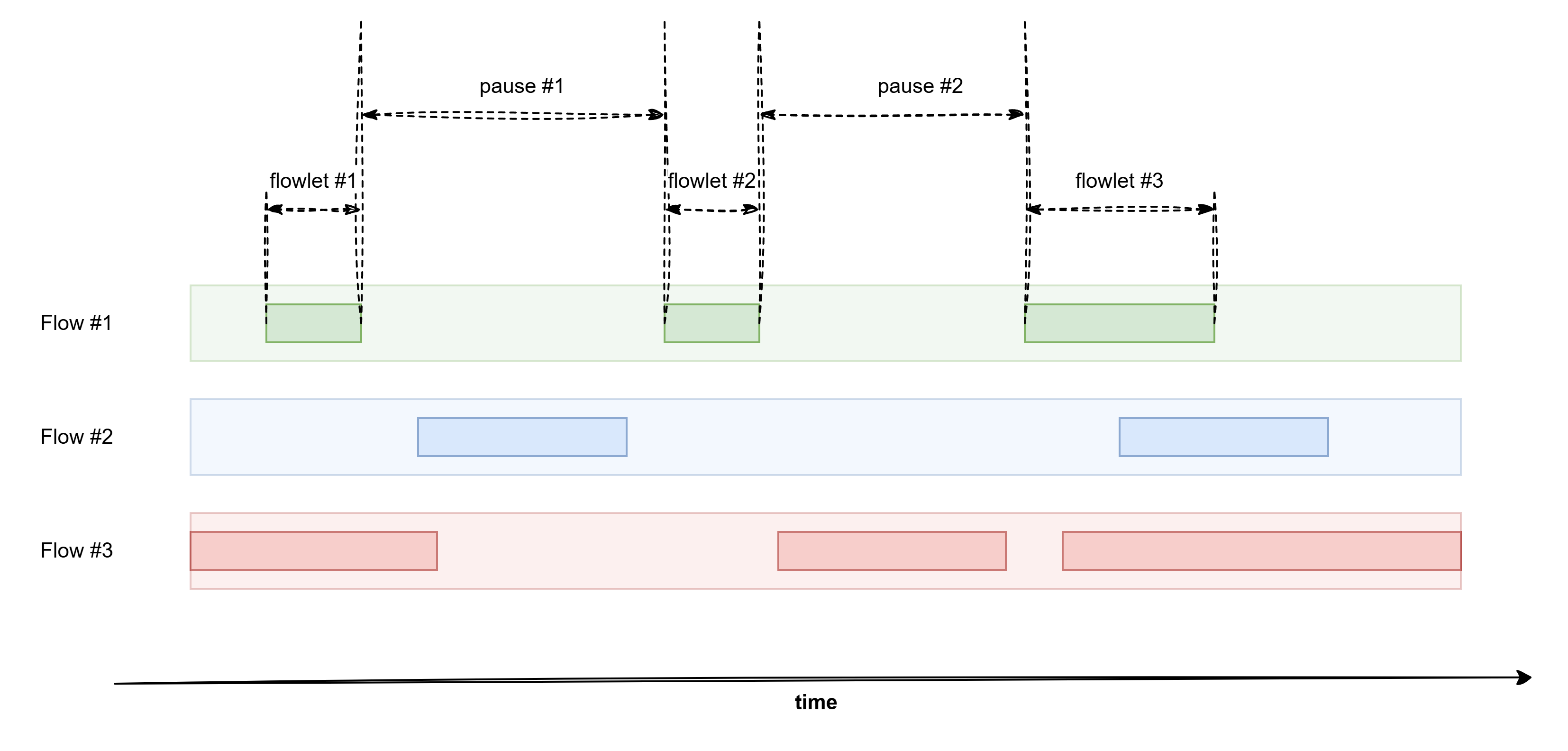
Тут условие только одно - главное чтобы фловлет номер 2 не прилетел раньше первого - иначе вообще фигня получится! Теоретически, такое может произойти если свитч решил отправит flowlet номер один через Австралию например (фигасе у вас фабрика!) - ну то есть по пути, задержка которого по сравнению с задержкой пути для второго флоулета, больше длительности паузы между ними. Ещё раз на пальцах:
- Допустим предполагаемая пауза между фловлетами - 50 мкс
- Для фловлета один выбран путь, по которому он приедет на 80 мкс
- Для фловлета два выбран путь, который достави его за 20 мкс
В момент времени t0 мы отправили фловлет номер 1 в путь. Он прибудет через 80 мкс. Подождали 50 мкс и отправили фловлет номер два в путь. Относительно момента t0, фловлет два приедет до хоста через 50+20 мкс = 70 мкс. То есть на 10 мкс раньше чем фловлет номер 1. Хотел сделать лучше, а получилось как всегда :(
В общем, идея хорошая но наша сеть тут должна обладать недюжим интеллектом:
- Нужно понимать вообще чё по латенси на альтернативных путях.
- Нужно уметь предсказывать длину пауз от только что прибывшего кусочка до следующего. Выглядит как задача для AI, ну то есть для серьёзной математики. Ознакомится с серьёзностью математики предлагаю вот тут - https://www.eecs.umich.edu/courses/eecs589/papers/p503-alizadeh.pdf или вот тут - https://groups.csail.mit.edu/netmit/wordpress/wp-content/themes/netmit/papers/texcp-hotnets04.pdf Я такое не читаю, так как меня даже такие формулы начинают пугать в сетях
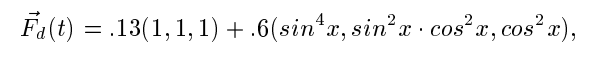
Вторая ссылка - один их первых документов по концепции фловлетов вообщем, первая - это про механимз CONGA, который является математической основой для цисковской реализации всей это магии, которая называется Dynamic Load Balancing и применяется в ACI. Ну кстати, да, кажется в SDN-е таким вещам самое место. А вот Juniper не парится и вполне себе несёт это всё в железную фабрику, обозвав Адаптивная Балансировка. Juniper молодец - будь как Juniper!
Ах, да кажется что применять такой подход для среды с Anycast-овыми сервисами стоит с некоторой осторожностью - не факт что ваша фабрика в теме, что за разными путями могут скрываться РАЗНЫЕ сервера - в итоге ваши TCP сессии будут регулярно разваливаться с таким подходом. Но я хз - я лично такое в проде пока не встречал, в основном теоретизирую тут. Встречал ли кто-то? Мне кажется нет и это всё пиздёшь)
ВЫВОДЫ
Помнить что серебряной пули нет
Анализировать ваши требования к сервису, ваш паттерн трафика
Применять гибридные подходы - на каком-то участке использовать один тип балансировки, где-то другой
Изучать и исправлять ошибки
Всё, расходимся. Тут не на что больше смотреть